Débugue tes humanités
Plan de la séance #
- Sauvegarder des données, pourquoi ?
- Quelques principes pour la sauvegarde de nos données
- Les types de sauvegarde
- Rsync : synchronisé vite et bien
- Chaîne de sauvegarde
1. Sauvegarder des données : pourquoi ? #
sauvegarder, verbe transit.
Conserver, maintenir intact quelque chose.
CNRTL
La grande question est celle de savoir pourquoi nous avons besoin de sauvegarder des données, cette interrogation peut être divisée en plusieurs points :
- que se passe-t-il si je perds mon ordinateur ?
- que se passe-t-il si ma maison brûle ?
- est-ce que je veux pouvoir accéder à mes données dans 10 ans ?
- est-ce que j’ai besoin de retrouver une ancienne version d’un fichier ?
- qui a besoin d’accéder à mes données et quand ?
- etc.
2. Quelques principes pour la sauvegarde de nos données #
- plusieurs types de données
- la fréquence
- les lieux/plateformes de stockage
- la vérification
2. Quelques principes #
2.1. Plusieurs types de données #
- données actives : utilisations/modifications fréquentes
- projets actifs
- textes en cours d’écriture
- annotations
- bases de données (corpus, données bibliographiques, etc.)
- etc.
- projets actifs
- données archivées : accès principalement en lecture
- livres et documents à consulter (sans annotation)
- musique et vidéo
- projet ancien/inactif
- images
- etc.
- livres et documents à consulter (sans annotation)
Dans le premier cas il s’agit de données qui doivent être accessibles très régulièrement en lecture et en écriture : il ne s’agit pas seulement de pouvoir y accéder mais aussi de devoir les modifier. Ces données doivent être sauvegarder fréquemment pour pouvoir retrouver les modifications du jour (par exemple).
Dans le second cas il s’agit d’informations qui vont être rarement modifiées, par exemple dans le cas d’un projet passé et terminé.
Une bonne façon de faire la différence entre les deux est de se poser la question suivante : si je perds mon ordinateur et que j’ai besoin d’accéder à un fichier :
- est-ce que cet accès est urgent ?
- est-ce que c’est un problème si je retrouve une version de ce fichier d’il y a 2 mois ?
Une donnée peut passer d’active à archivée et inversement. Idéalement, l’organisation sur votre ordinateur peut refléter cette distinction.
2. Quelques principes #
2.2. La fréquence #
- moins d’une heure : synchronisation continue
- moins d’un jour : synchronisation régulière
- moins d’un mois : synchronisation ponctuelle
2. Quelques principes #
2.3. Les dispositifs/lieux/plateformes de stockage #
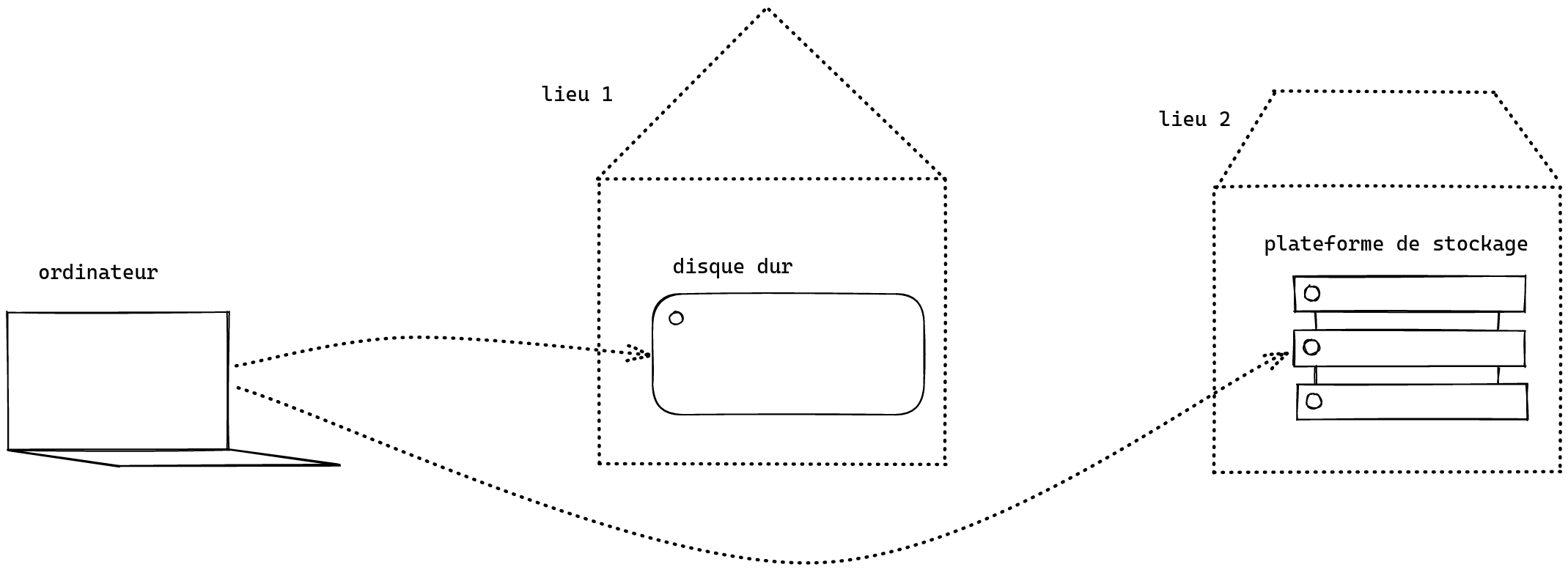
2. Quelques principes #
2.3. Les dispositifs/lieux/plateformes de stockage #
- votre ordinateur (portable ou non) : par défaut le dispositif qui produit et contient les données
- disque dur : avec vous, chez vous, chez quelqu’un d’autre
- des lieux physiques : votre maison, d’autres lieux
- plateforme en ligne : l’ordinateur de quelqu’un d’autre accessible en ligne
Cette distinction permet de Si vous avez un chez vous (une maison, un appartement, un lieu de vie abrité dans lequel vous pouvez vous rendre régulièrement et dans lequel vous pouvez conserver un disque dur sans crainte), alors vous pouvez y stocker votre ordinateur et un disque dur. Ce point est important : il faut déterminer des espaces physiques que vous connaissez pour pouvoir y stocker un ou plusieurs disques durs.
J’écarte ici les dispositifs du type tablette ou téléphone intelligent, ils ne constituent pas des dispositifs de stockage et de sauvegarde, trop instables et peut-être trop mobiles.
2. Quelques principes pour la sauvegarde de nos données #
2.4. La vérification #
La partie la plus délicate :
- est-ce que les données ont toutes été copiées ?
- est-ce que le support de stockage fonctionne bien ?
- plusieurs solutions : vérifications par échantillonnage notamment.
3. Les types de sauvegarde #
- sauvegarde : copie conforme (copié/collé)
- synchronisation : copie si modification
- fréquence : continue/régulière/ponctuelle
- versionnement : conservation d’un historique
4. rsync : synchronisé vite et bien #
rsync remote synchronization, (en français : « synchronisation distante ») est un logiciel libre de synchronisation de fichiers, distribué sous licence GNU GPL. La synchronisation est unidirectionnelle, c’est-à-dire qu’elle copie les fichiers de la source en direction de la destination. rsync est donc utilisé pour réaliser des sauvegardes incrémentielles ou différentielles ou pour diffuser le contenu d’un répertoire de référence.
Pourquoi utiliser rsync ? Parce que c’est un moyen simple et très efficace de sauvegarder et mettre à jour ses données. Et notamment en gardant la trace : des dates de publication précises (conservées au moment de la copie) et des droits d’utilisation (très utile). Par ailleurs le fonctionnement de rsync est tel qu’une sauvegarde d’un ordinateur ne prend que quelques minutes (à partir de la deuxième sauvegarde) :
- rsync est capable de comparer les fichiers d’origine et ceux conservés sur le deuxième support/dispositif ;
- si aucune modification n’a été faite sur un fichier, rsync ne le copie/colle pas ;
- ainsi un fichier lourd ne sera pas copié à chaque sauvegarde.
Pour donner un exemple : la sauvegarde complète de mon ordinateur (400Go) avec rsync sur un disque dur prend environ 15 minutes.
Le logiciel (avec interface graphique) peut vous faciliter l’utilisation de rsync (d’habitude utilisé en ligne de commande) : https://www.opbyte.it/grsync/, a priori le logiciel est également disponible sous Mac et Windows.
5. Chaîne de sauvegarde #
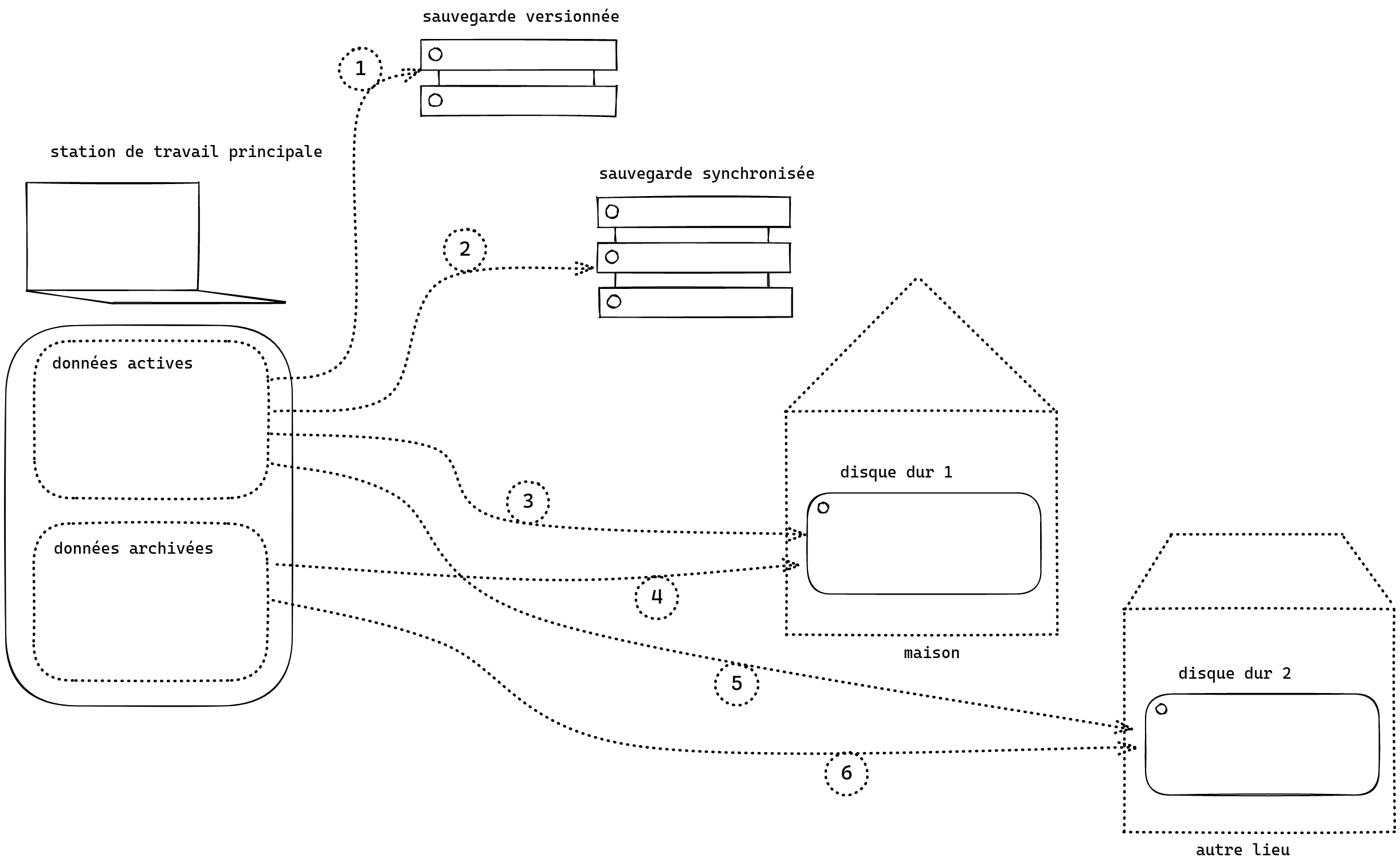
- fichiers versionnés (typiquement avec Git) et sauvegardés sur un serveur distant (comme GitHub, l’instance GitLab d’Huma-Num, etc.). À chaque versionnement je peux envoyer mes données sur un autre serveur, qui va conserver les fichiers et l’historique des modifications. Pour les fichiers très lourds, pensez à Git LFS ;
- données actives synchronisées en temps réel : dès que je fais une modification un logiciel synchronise mes fichiers (Dropbox, Nextcloud, etc.) ;
- données actives sauvegardées régulièrement avec rsync et éventuellement un script qui fait la sauvegarde à un moment précis ;
- même chose pour les données archivées ;
- données actives sauvegardées sur un second support ;
- idem pour les données archivées.
Pour résumer voici la liste des actions nécessaires :
- envoi des fichiers versionnés lorsque je travaille dans un dépôt Git ;
- synchronisation des données actives sans intervention (vérifier tous les mois que les données sont lisibles via un accès en ligne) ;
- une fois par semaine/mois : sauvegarde sur un premier disque dur avec rsync ;
- une fois par mois : sauvegarde sur un second disque dur avec rsync également.
Débugue tes humanités
CC BY-NC-SA Chaire de recherche du Canada sur les écritures numériques, Bibliothèque des lettres et des sciences humaines, Ouvroir d'histoire de l'art et de muséologie numérique. — antoine.fauchie@umontreal.ca