Sommaire
# Plan de la séance
- Qu’est-ce qu’une « donnée structurée » ? Pourquoi est-ce utile ?
- Le format CSV et Microsoft Excel (XLSX) : qu’est-ce qui est quoi ?
csvkit: le couteau suisse pour manipuler des tableaux CSV
Un mot sur les notions : bien qu’il ne soit ne soit pas nécessaire d’assister aux séances précédentes de Débogue tes humanités, cette séance fera appel à certaines notions importantes : comprendre les dossiers et les fichiers sur son ordinateur (fondamental !), les formats, et même le terminal pour les plus aventureux·ses !
🧠 Rappelez-vous que nous ne cherchons pas à enseigner l’utilisation d’outils spécifiques, mais plutôt des stratégies qui vous permettent d’accroître votre littéracie numérique – quels que soient les outils que vous utiliserez ! C’est comme apprendre à cuisiner : mieux vaut apprendre comment mélanger les ingrédients que d’apprendre à utiliser l’appareil d’une marque en particulier !
# 1. Qu’est-ce qu’une « donnée structurée » ?
Une donnée structurée est une donnée balisée dans un format standardisé, ce qui lui permet d’être facilement lue par une machine ou un être humain. On en retrouve dans :
- 📄 les documents textuels :
- les titres de chapitres d’un roman ou les noms des personnages balisés dans une pièce de théâtre (ce qui permet de générer automatiquement une table des matières ou un index des personnages) ;
- ☎️ les carnets d’adresses :
- prénom, nom, numéro de téléphone, adresse courriel, etc. ;
- 📷 les appareils photo :
- la date de prise de vue, le profil de couleur, les coordonnées géographiques, etc. ;
- 📚 les catalogues de bibliothèque :
- elles permettant d’effectuer une recherche par titre, auteur, sujet, etc.
Bref, les données structurées sont partout et existent sous une myriade de formes !
# 1.2 Exemple de données structurées : les chansons en format numérique
Les catalogues de chansons regorgent de données structurées ! Celles-ci sont nécessaires pour permettre l’affichage des bonnes informations dans le lecteur de musique (comme la durée, le numéro de piste ou la pochette de l’album), effectuer le tri (par artiste, par album, par année) ou même produire des recommandations (en fonction du genre ou du nombre d’écoutes).
Capture d’écran d’une liste de lecture. Les champs qui utilisent des données structurées ont été encadrés.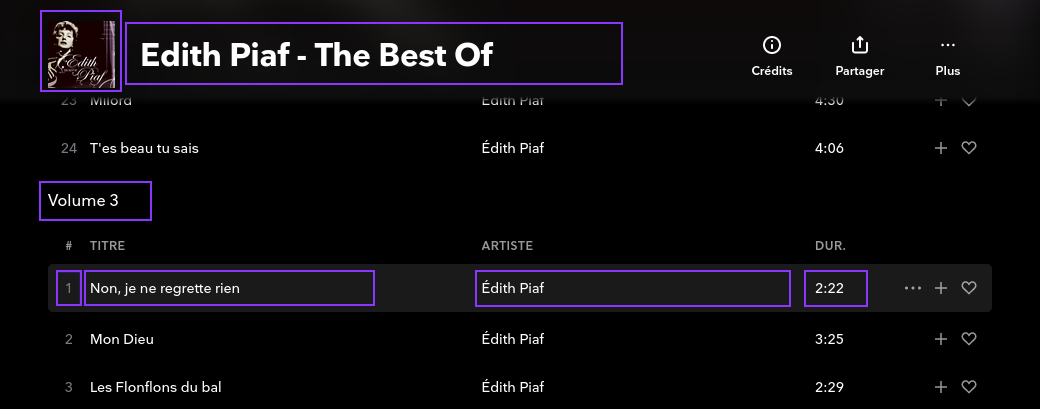
Vous pouvez vous-même inspecter les métadonnées d’un fichier audio en accédant à ses « propriétés », ou en l’ouvrant dans un logiciel dédié aux contenus multimédias.
Capture d’écran d’une fenêtre d’inspection des métadonnées d’une pièce musicale. Les informations de titre, album, éditeur, etc. peuvent être saisies dans des champs séparés.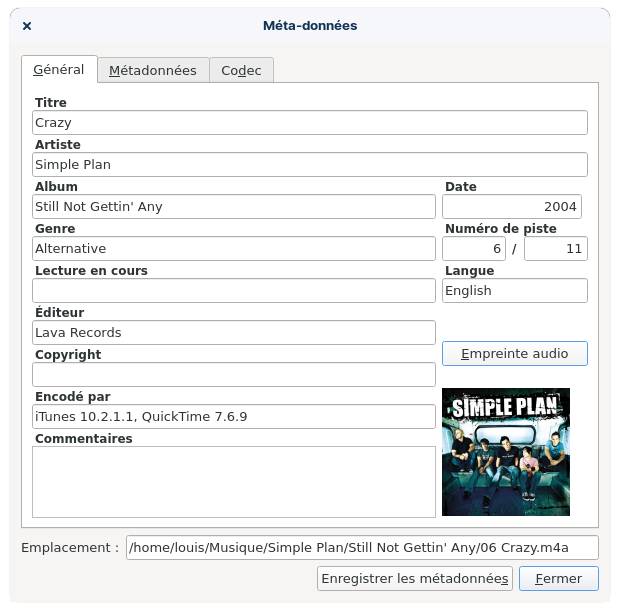
# 1.3 Exemple de données structurées : les moteurs de recherche
Les moteurs de recherche construisent des modèles de représentation (knowledge graphs) de l’information. C’est grâce à eux qu’ils peuvent produire des pages de résultats davantage structurées.
Capture d’écran d’une simple recherche en ligne. Les champs qui utilisent des données structurées ont été encadrés.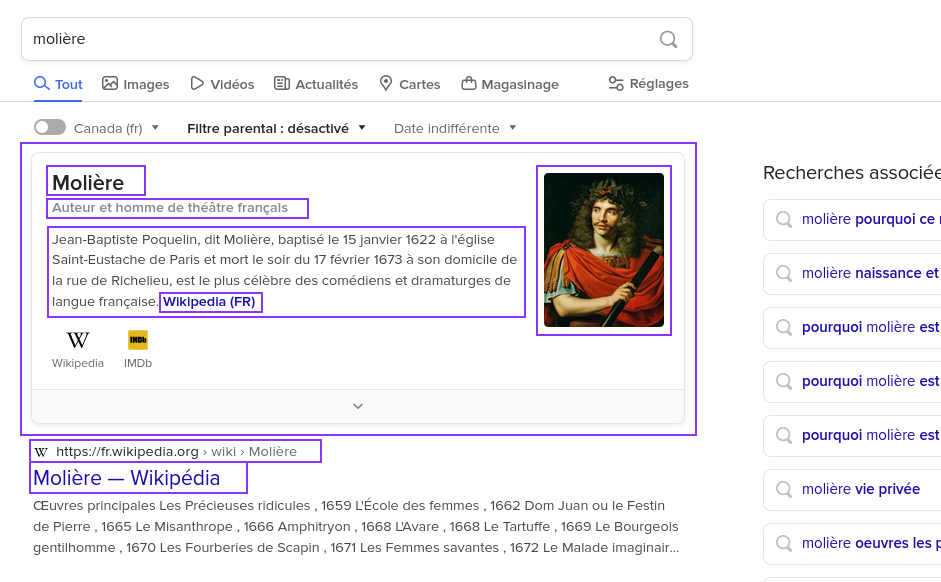
# 1.4 Exemple de données structurées : les publications scientifiques
La publication scientifique évolue dans un contexte de massification importante de l’information, et l’accès à une information de qualité devient un enjeu plus criant que jamais.
Il est crucial de veiller à ce que les ouvrages et articles soient facilement découvrables grâce à des données « propres » et surtout bien structurées : noms des auteurs et autrices, date de publication, mots-clefs, résumés – sans ces informations (et bien d’autres !), un document a peu de chances d’être trouvé ou consulté.
Capture d’écran d’un article dans l’éditeur Stylo. Les métadonnées de l’article (auteur, résumé, mots-clefs, etc.) peuvent être saisies dans le panneau latéral de droite.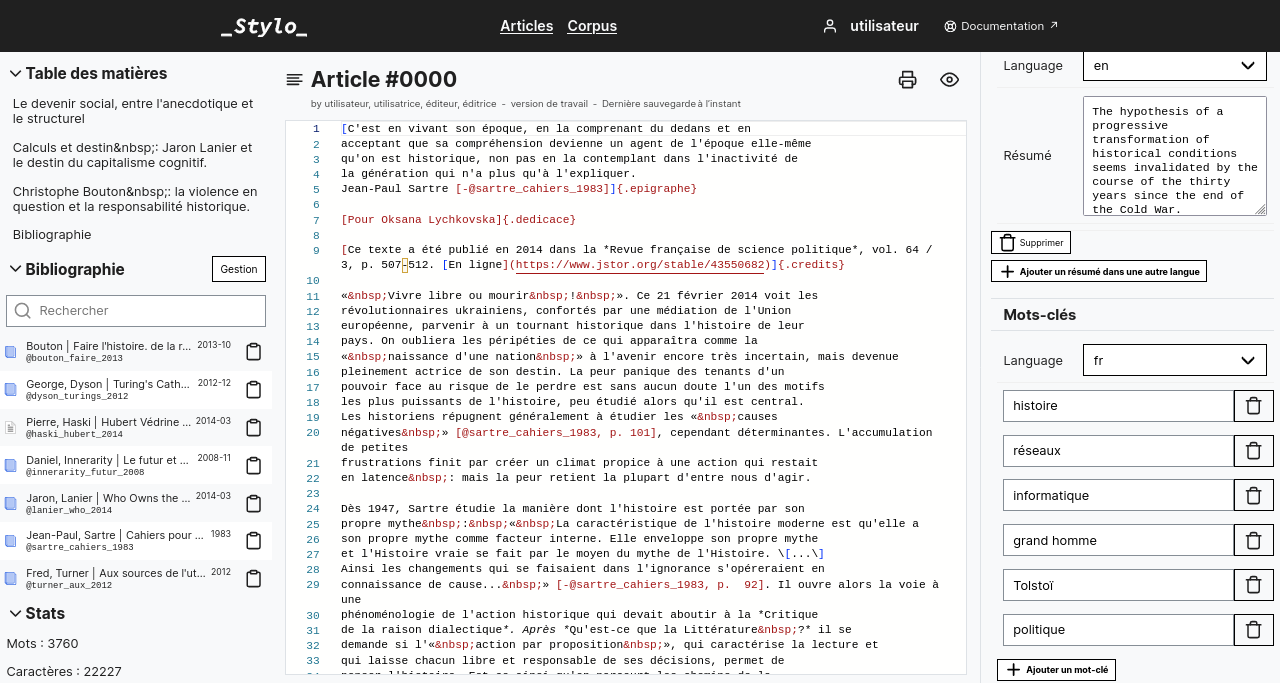
Capture d’écran de la page couverture article scientifique en format PDF distribué par la plateforme Érudit. Le document contient de nombreuses données structurées qui facilitent son indexation et sa découvrabilité.
# 1.5 Les tableaux : une représentation couramment utilisée pour les données structurées
On retrouve souvent des ensembles de données structurées dans des tableaux. Le type de donnée est alors défini par le nom de la colonne dans laquelle l’information se trouve.
La première rangée d’un tableau est généralement son « en-tête », avec les noms de colonne.
# 2. Le format CSV et Microsoft Excel (XLSX) : qu’est-ce qui est quoi ?
Dans les formations de Débogue tes humanités, nous nous intéressons souvent aux formats de représentation des différentes données : texte / texte brut, HTML, XML, DOCX, PDF…
Ici, nous nous attardons en particulier à des formats pour les données tabulaires.
Comment procédez-vous pour traiter des tableaux ? Quels outils utilisez-vous ?
# 2.1 Le format XLSX
Le format de fichier utilisé par le tableur Microsoft Excel fait l’objet d’un standard officiel (ISO/IEC 29500-1:2016), encadré par l’organisation internationale de standardisation (ISO). Et le document de cette spécification fait… plus de 5000 pages !
De la même manière que DOCX utilisé par le logiciel de traitement de texte Microsoft Word, un fichier XLSX n’est rien d’autre qu’un paquet .ZIP contenant de nombreux fichiers XML (il s’agit de la même spécification pour tous les fichiers de la suite Microsoft Office).
.ZIP (format cité dans la spécification Office Open XML) est considérable, même s’il n’est utilisé que pour « empaqueter » des fichiers :https://pkwaredownloads.blob.core.windows.net/pkware-general/Documentation/APPNOTE_6.2.0.TXT
Extrait du préambule de la spécification pour le format Office Open XML. De nombreux autres standards sont utilisés, comme XML et ZIP.
Aperçu des fichiers constituant un document XLSX dans lequel on a écrit « Colonne A » dans une cellule.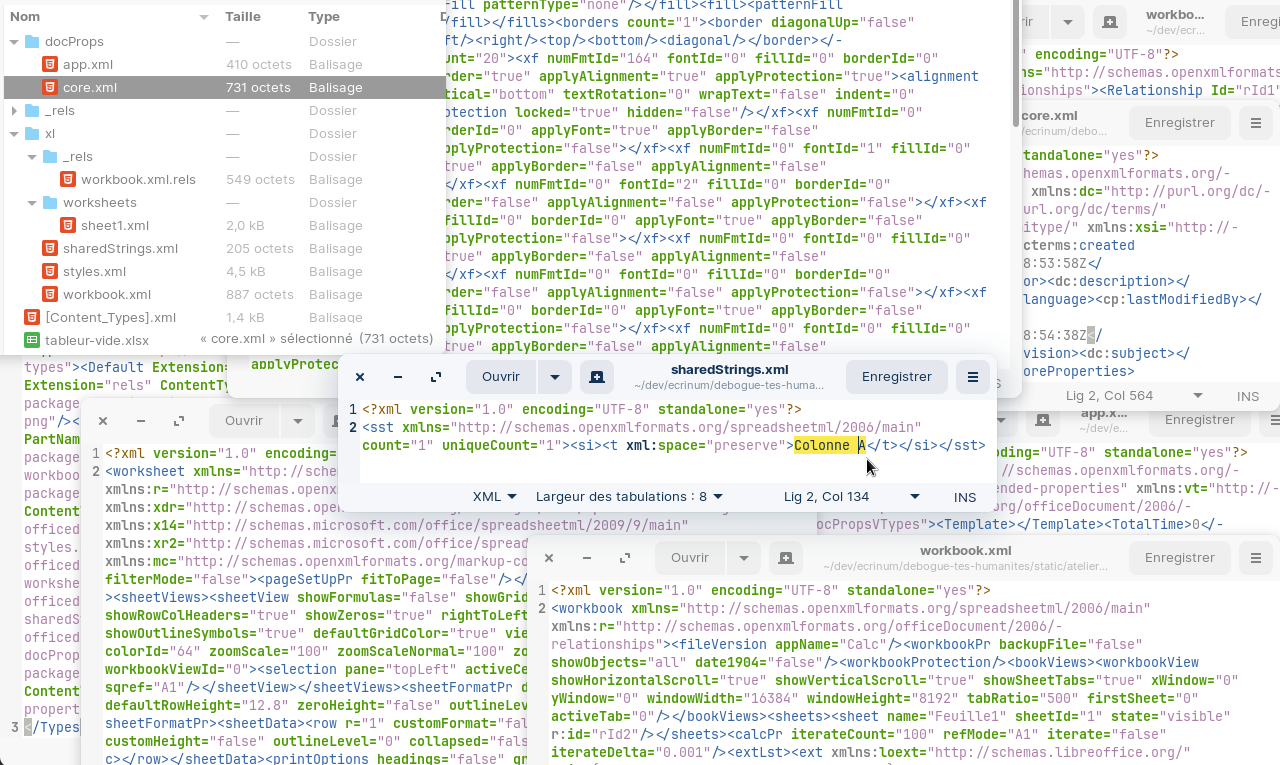
Le logiciel Microsoft Excel s’avère pratique dans bien des cas (pour effectuer des transformations, des calculs complexes ou des tableaux croisés dynamiques), mais son format de fichier associé XLSX est-il toujours le meilleur pour stocker des données tabulaires ?
N’y aurait-il pas un format plus simple, compréhensible et pérenne ?
# 2.2 Le format CSV
CSV est l’acronyme de Comma-Separated Values (« valeurs séparées par une virgule »). Il s’agit d’un format texte brut qu’on peut ouvrir avec n’importe quel éditeur de texte (Notepad sur Windows, TextEdit sur macOS, gedit sur Linux, et une myriade d’autres…).
Voici à quoi pourrait ressembler un fichier CSV* :
Colonne A, Colonne B, Colonne C, Colonne D
A, B, C, D
A, B, C, D
A, B, C, D
* Des espaces ont été ajoutées à des fins d’alignement visuel.
… et sa correspondance :
Mais qu’arrive-t-il si une cellule contient une virgule ?!
Pas de problème !
Dans les faits, un fichier .csv ressemble plus souvent à ceci, avec des guillemets droits " " qui encadrent le texte de chaque cellule pour éviter les erreurs de délimitation :
"Colonne A","Colonne B","Colonne C","Colonne D"
"A","B","C","D"
"A","B","C","D"
"A","B","C","D"
# 2.3 Créez (facilement !) votre premier tableau CSV !
Essayez d’exporter un tableau en format CSV depuis votre logiciel de tableur préféré.
Ce format apparaîtra peut-être sous le libellé « Texte (délimité par des virgules) », « Texte CSV » ou autre dans le menu déroulant des formats de sauvegarde.
Boîte de dialogue lors de l’enregistrement au format texte (CSV) dans le logiciel LibreOffice.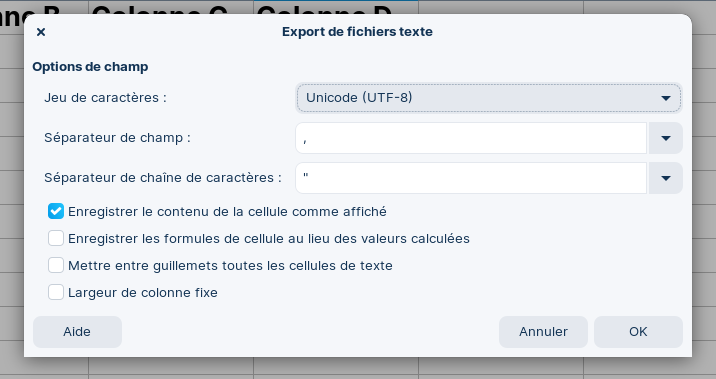
Enregistrez votre tableau dans un dossier que vous créerez pour cet exercice (rappel : il est important de comprendre l’emplacement des fichiers sur son ordinateur !) et essayez de l’ouvrir avec votre éditeur de texte préféré, ou encore avec le terminal :
# Dans un terminal, déplacez-vous d'abord dans le
# répertoire pour votre exercice, par exemple:
# cd ~/Documents/exercice-csv
# Ensuite, examinez le contenu de votre fichier CSV
# (remplacez "mon-tableau.csv" par le nom de votre fichier)
cat mon-tableau.csv
# (le contenu de votre fichier s'affichera ici!)Bravo ! Vous avez créé votre premier fichier CSV. Ce type de fichier, comme vous l’avez constaté, est extrêmement simple et permet de stocker une grande quantité de données tabulaires.
C’est un format qui permet une interopérabilité significative entre des systèmes d’information : il est beaucoup plus facile d’importer/exporter des données en format CSV.
Des services populaires comme Airtable ou Notion permettent d’importer ou d’exporter ses données en format CSV. On peut ensuite facilement les intégrer dans un tableur, ou en faire autre chose, comme des visualisations de données !
# 2.4 Un exemple d’utilisation de données CSV : les actes criminels sur le territoire de la ville de Montréal
Le jeu de données est accessible librement sur le site de Données Québec.
Exemple de tableau : crimes répertoriés sur le territoire du service de police de la ville de Montréal.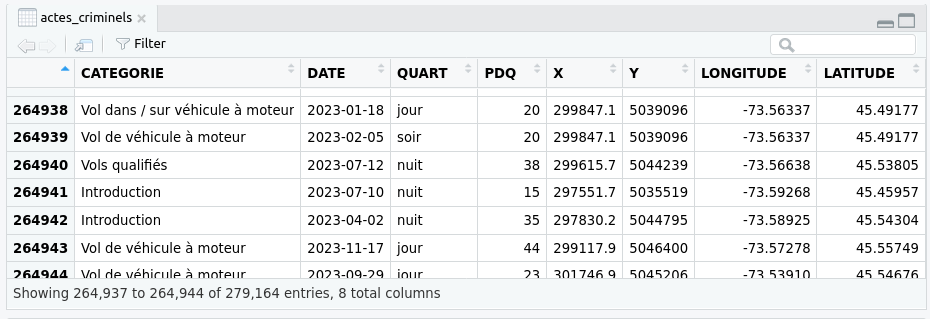
Visualisation des données tabulaires avec le langage de programmation R (dans RStudio). D’après un atelier préparé par Lisa Theichmann.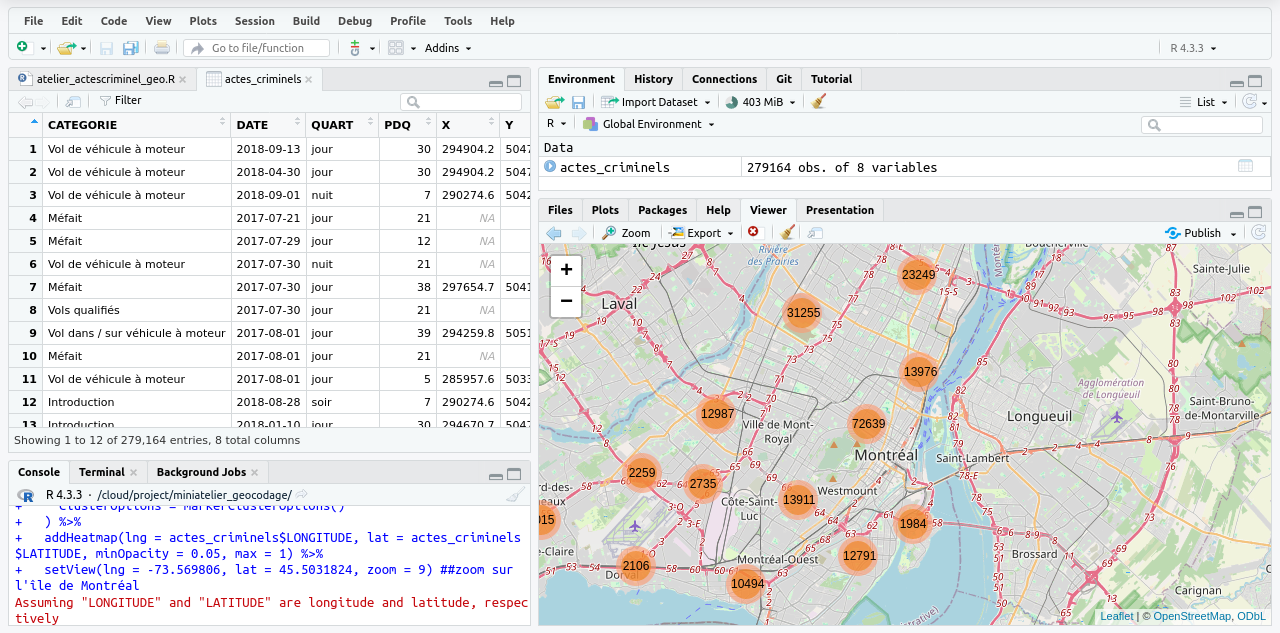
# 3. csvkit: le couteau suisse pour manipuler des fichiers CSV
Pour clore cette formation, nous vous proposons la démonstration d’un outil très puissant, qu’on peut utiliser dans la ligne de commande : csvkit.
Il s’agit en réalité d’une boîte contenant plusieurs outils, qu’on peut utiliser séparément ou conjointement en combinant les commandes.
# 3.1 Installation de csvkit
Le logiciel est écrit en langage Python (version 3) ; ce langage doit être installé sur votre poste pour que vous puissiez utiliser csvkit.
Python est déjà installé sur votre machine
Si Python est installé sur votre machine, vous pouvez installer csvkit avec le gestionnaire de paquets Python pip :
#!/bin/bash
sudo pip install csvkitsudo dans la commande précédente vous permet d’installer le logiciel sur votre système (au lieu de simplement le télécharger pour un projt isolé).
Votre mot de passe d’utilisateur (sur votre poste) vous sera demandé, et il est possible que les caractères ne s’affichent pas lorsque vous le tapez (c’est normal !).
Python n'est pas installé sur votre machine
Cela dépasse le cadre de cet atelier : rendez-vous sur le site web de Python pour en savoir plus.
# 3.2 Premiers pas avec csvkit
csvkit propose un excellent tutoriel pour débuter facilement.
Quelques commandes couramment utilisées :
csvcut✂️ :- L’utilitaire original qui a donné lieu à la suite d’outils. On s’en sert pour découper une partie du fichier – comme si on prenait une paire de ciseaux.
csvstat📊 :- Permet de résumer les colonnes d’un fichier et d’en produire des statistiques.
csvlook👀 :- Un « périscope » pour examiner le contenu d’un fichier CSV (très utile lorsque combiné avec la commande
less -S!)
# 3.3 Un jeu de données pour expérimenter
Il nous faudrait des données à nous mettre sous la dent ! Utilisons un outil que nous connaissons bien : le gestionnaire de références bibliographiques Zotero.
Nous allons exporter une collection en sélectionnant CSV comme format de sortie.
Nous sauvegarderons le fichier sous le nom de bibliotheque.csv (c’est notre bibliothèque de références) dans le répertoire que nous avons créé pour cet atelier.
# répertoire pour cet exercice
exercice-csv/
├── bibliotheque.csv # <-- nous allons utiliser ce fichier!
├── mon-tableau.csv
└── mon-tableau.xlsx
Que contient notre fichier bibliotheque.csv ?
Dans le terminal, on peut « découper » les en-têtes de colonnes :
# bash
csvcut --names bibliotheque.csv
On pourrait produire des statistiques sur certaines colonnes (avec le drapeau --columns ou -c), comme le type de document, dénoté par le champ "Item Type" :
# bash
csvstat --columns "Item Type" bibliotheque.csv
Visualisons le fichier directement dans le terminal, en combinant la commande avec l’utilitaire less :
- l’argument
-Spermet d’éviter les retours à la ligne et de défiler avec les flèches du clavier ; - l’argument
-#permet de régler la « vitesse » du défilement (2,6,10…) lorsqu’on appuie sur une touche.
# bash
csvlook bibliotheque.csv | less -S -#2
Il y a tant de choses que la boîte à outils de csvkit permet de faire.
Suivez leur tutoriel ou référez-vous à la documentation pour en savoir plus!
# Conclusion
Nous espérons que vous aurez compris l’atout d’utiliser le format CSV pour stocker vos données tabulaires. La simplicité, la malléabilité et l’interopérabilité de ce format en font un candidat idéal pour vos projets, petits ou grands, et ses applications sont très nombreuses ! C’est un format texte brut facile à lire et facile à archiver, ce qui en fait un gage de pérennité.