IA et la correction textuelle automatique : quels outils et quelles limites ?
Les outils d’IA générative se sont désormais immiscés dans tous nos logiciels d’édition, aussi bien pour la rédaction de mail, de documents textuels que pour de l’assistance à la rédaction de fiction ou de dissertation, mais comment faire la différence entre toutes les formes de corrections possibles et mesurer l’intérêt et l’impact de ces outils dans nos pratiques. Cet atelier vise à outiller les chercheur.se.s en SHS sur les outils existants et offrir des pistes pour mesurer leur impact dans leurs pratiques individuelles.
Chaire de recherche du Canada sur les écritures numériques, Bibliothèque des lettres et des sciences humaines, Centre de recherche interuniversitaire sur les humanités numériques. — louis-olivier.brassard@umontreal.ca
Plan de l’atelier
Théorie :
- Rappels sur les fondements de l’IA
- Mise en perspective
- Définition et présentation historico-technique des systèmes de GEC
- Enjeux/conséquence
- Présentation de certains outils
- Conclusion/ce qu’il faut retenir
Introduction
Présentation et objectif des ateliers
Format : 4 séances de 2 heures, sans inscription, participation libre (à justifier pour le certificat des Humanités Numériques)
Théorie et pratique.
Objectifs de la série d’atelier :
- Comprendre les fondamentaux de l’IA et son histoire
- Obtenir des notions critiques sur le fonctionnement profond des outils
- Tester et s’approprier des outils d’IA
- Maîtriser le vocabulaire de la discipline
Objectifs de cet atelier :
- Cerner un cas d’usage courant des IA génératives : la correction ortho-typographique.
- Contextualiser la correction (automatique)
- S’interroger sur l’impact de ces nouvelles pratiques dans le travail de recherche.
- Définir des critères pour effectuer un choix éclairé vis-à-vis des outils disponibles.
Certificat canadien en Humanités Numériques

Certificat canadien en Humanités Numériques

IA et révision
En quoi les outils d’aide à la rédaction basés sur l’IA transforme-t-ils le rapport des chercheur·euses à leur texte, au processus d’écriture et aux ?
Nous aborderons :
- l’histoire et la pratique de la correction,
- le basculement technique (du savoir-faire de l’ortho-typo à la reformulation automatisée),
- les enjeux épistémologiques (déprise du texte),
- et les enjeux sociolinguistiques.
Les fondamentaux : rappels de l’introduction
Qu’est ce que l’IA ?
Des programmes informatiques que nous estimons à la hauteur de l’intelligence humaine ? Le développement des technologies fait évoluer cette définition de l’intelligence non seulement artificielle mais aussi humaine.
‘IA’ depuis 5 ans, a remplacé le ’numérique’ des années 2010, et le ‘cyberespace’ des années 1990 et 2000. (Citation: Vitali-Rosati, 2025) Vitali-Rosati, M. (2025). Manifeste pour des Études Critiques de l’Intelligence Artificielle. Consulté à l’adresse http://blog.sens-public.org/marcellovitalirosati/manifeste-ecia.html .
Définition pratique pour ces ateliers: “un programme informatique qui effectue une prédiction.”
Rappels de l’introduction
- Les programmes d’IA réfèrent à des processus algorithmiques variés et pas seulement à des chatbots type ChatGPT.
- L’IA est une discipline qui a plus de 75 ans (terme de 1956).
- (Citation: Turing, 1950) Turing, A. (1950). Computing Machinery and Intelligence. Mind, LIX(236). 433–460. https://doi.org/10.1093/mind/LIX.236.433 a orienté la discipline vers un modèle ‘chatbot’.
- Les ‘saisons de l’IA’ suivent des phases d’approbation publique et de désintérêt pour le terme et les technologies qu’on place sous ce terme.
- Ce qu’on fait entrer dans la catégorie d’“intelligent” a changé : le calcul savant est-il moins intelligent que le bavardage ?
Rappels historiques sur l’IA
- Deux grandes approches en IA : une approche déductive (IA symbolique, système expert) vs. approche inductive (IA connexionniste, modèle de langue).
- Un système expert peut être aussi complexe et énergivore qu’un LLM.
- Un LLM (large language model) est la modélisation sous forme de vecteurs de chaque élément d’un grand corpus (token ~mot) par rapport à cet ensemble.
Les LLMs en contexte
- Pour les LLMs, la ‘compréhension’ du monde n’est basée sur aucun référent ou aucune règle définie : les réponses sont probabilistes.
- Les hallucinations ne sont pas des anomalies, ce sont des erreurs que l’on qualifie a posteriori comme telle.
- Après l’apprentissage de son corpus d’entrainement, une étape de reinforcement learning donne une saveur ou personnalité à un modèle.
- Les LLMs reflètent les intérêts économiques de leurs concepteurices: nature ‘sycophantique’ avérée.
- On peut influencer le calcul de probabilité d’un modèle (température, top-k, seed) et donc sa personnalité (déterministe vs. créatif).
- On peut aussi ‘orienter’ le comportement d’un modèle avec un system prompt.
- Chatbots = interfaces en langue naturelle : l’exploitation des capacités inductives d’un LLMs ne nécessite pas de passer par une telle interface. Ex : classification avec de l’apprentissage machine (machine learning).
Mise en perspective
C’est quoi la correction / révision ?
Historique technique des outils
Essayons de définir…
D’après le TLFi → CORRECTEUR, TRICE, subst. et adj.
Homme, femme qui s’arroge ou à qui est dévolu le rôle de corriger des défauts, de rectifier des erreurs sans pour autant infliger de punition corporelle.
TYPOGR. Ouvrier spécialisé qui, dans une imprimerie, est chargé de lire et de corriger les épreuves. Les correcteurs ont deux maladies, les majuscules et les virgules, deux détails qui défigurent ou coupent le vers (HUGO, Corresp., 1859, p. 298).
Rem. 1. a) D’après la fonction, on distingue du correcteur qui révise les épreuves d’un journal le correcteur de labeur qui révise celles d’un ouvrage. b) D’après la hiérarchie on distingue les correcteurs en première (première épreuve), les correcteurs en second (ou en bon à tirer), les correcteurs en tierce (après la mise sous presse). 2. “Le correcteur femme existe aussi; mais cette espèce, du reste très rare”, travaille non pas dans l’atelier typographique, mais “au bureau du patron ou du prote” (d’apr. BOUTMY, Typogr. paris., 1874, p. 29). Sainte-Beuve dans la salle à manger, en famille, avec son secrétaire Troubat, sa correctrice d’épreuves, sa maîtresse (GONCOURT, Journal, 1867, p. 365).
TECHNOL. [Désigne un dispositif]
B. [L’instrument (matériel) de la correction dans diverses techniques]
C. [Le résultat lui-même]
On peut relever un certain nombre de tensions
- Entre l’homme et l’outil
- Entre l’outil et le résultat
J’en rajoute une autre : entre deux espace-temps différents :
- les protocoles éditoriaux établis au sein d’institutions
- les pratiques de brouillonnages individuelles
1. La révision comme protocole éditorial
Définition donnée par le Correcteur typographe de Brossard de 1924 :
La rectification, sur le plomb, des erreurs commises par le compositeur, ainsi que l’exécution des changements apportés par l’auteur à la composition du texte primitif sont connus sous la dénomination de correction. De, manière générale, ce mot s’emploie pour désigner toute modification, quelle, qu’elle soit : ajoutés, suppressions, transpositions, changements de texte, rectifications orthographiques, rappels de règles typographiques, etc. (Citation: Brossard, 1924) Brossard, L. (1924). Correcteur typographe. Les règles typographiques / L. -E. Brossard.
- Un savoir-faire qui nous vient du monde de l’imprimé
- Passer de la copie à l’ouvrage
- application des règles typographiques + reproduction fidèle et entière du manuscrit
- un processus séquentiel (lecture → annotation → recomposition)
- un processus itératif (premières, secondes épreuves, tierces)
- un processus collectif (auteur.ice → correcteur.ice → auteur.ice → compositeur.ice)
Les auteurs ne se font point faute d’ailleurs de se prévaloir en ces circonstances de la liberté que leur accordent les usages, et l’on peut dire qu’en pratique le nombre des épreuves en placards ou en pages à fournir est illimité : suivant ses besoins, et sur sa demande, l’auteur peut recevoir successivement une première d’auteur, une deuxième, une troisième, et même plus si, d’après les corrections ou les modifications qu’il apporte au texte, il l’estime nécessaire : il est seul juge en cette matière, et généralement il ne remet le bon à mettre en pages ou, le cas échéant, le bon à tirer, que s’il répute le texte « amené à son état à peu près définitif ». (Citation: Brossard, 1924) Brossard, L. (1924). Correcteur typographe. Les règles typographiques / L. -E. Brossard.
Le correcteur est le chef d’orchestre de la fabrique du livre

Signes de correction ortho-typo
Les acteurs travaillent l’un après l’autre, faute après faute
La composition est un processus terriblement laborieux

La casse et la galée
Science ou artisanat ?
Une science ?
Recommandation de @ramatRamatTypographie2008 :
Nombre de lecture en correction
- une lecture très rapprochée pour découvrir les fautes d’orthographe et de typographie.
- relire le texte sans s’occuper des fautes déjà mentionnées, s’attacher au fond et non plus à la forme.
- Vérification des pages et des notes
- Figures et tableaux
- Vérification des énumérations
- Dates
- Veiller à l’homogénéité de l’écriture inclusive
- S’assurer que le système international d’unité est bien utilisé
- Uniformité des abbréviations et des noms propres
- Les capitales, les faces, la casse
- Emploi normé de la ponctuation
- Révision bibliographique
- La composition et la mise en page (qu’on laisse de côté aujourd’hui)
Un travail qui relève de l’artisanat ? voire un art ?
L’inobservation des règles typographiques est, après la coquille, l’une des causes les plus fréquentes de correction : ce fait tient à l’ignorance dans laquelle trop d’ouvriers se trouvent des principes les plus élémentaires de leur art, au dédain même qu’ils affectent à leur égard, à la volonté et au désir de certains auteurs de s’affranchir des prescriptions d’un métier dont ils ne connaissent que des « bribes », à la multiplicité et aussi à un défaut de précision et de, fixité de ces prescriptions : celles-ci semblent en effet varier presque à l’infini, avec chaque région, avec chaque ville, avec chaque maison, avec chaque correcteur et, hélas! presque avec chaque labeur ; chacun ou chacune, a une marche particulière, ou un ensemble de règles typographiques qui leur est propre : dédale sans fin où se perdent même les meilleures volontés et où s’égarent les esprits les plus avertis. (Citation: Brossard, 1924) Brossard, L. (1924). Correcteur typographe. Les règles typographiques / L. -E. Brossard.
2. La correction au cœur de l’écriture
On peut aussi entendre révision au sens psycholinguistique => désigne une étape dans le processus scripturaire, étape liée à celle de la planification et de la textualisation.
- la linguistique génétique ou philologie préfère le mot « variante »
- la didactique dira « correction »
- « retouche », « remords »
- individuelle et multiple
La continuité révision / écriture s’incarne dans les outils.
Les outils ne se contentent plus de pointer, on est dans le paradigme de la génération de texte.
L’écriture et le numérique
Rapidité
(Citation: Derrida, 2005) Derrida, J. (2005). Paper Machine. Stanford University Press.It’s a different kind of timing, a different rythm. First of all you correct faster and in a more or less indefinite way. Previously, after a certain number of versions (corrections, reasures, cutting and pasting, Tippex), everything came to a halt – that was enough. Not that you thought the text was perfect, but, after a certain period of metamorphosis, the process was interrupted. With the computer, everything is rapid and so easy; you get to thinking that you can go on revising forever. An interminable revision, an infinite analysis is already on the horizon […]. During this same time you no longer retain the slightest visible or objective trace of corrections made the day before.
There was a temporal resistance, a thickness in the duration of erasure.
Correcteurs orthographiques et grammaticaux
- Facilité et rapidité de la correction ou révision
- Développement des outils de correction // développement des traitements de texte
- Logique de productivité
Les outils incarnent une vision du monde centrée sur la productivité et la rapidité
Histoire de la GEC
La correction d’erreur grammaticales automatique Grammar Error correction
Tâche de Traitement Automatique des Langues (TAL ou Natural Language Processing, NLP) voisine de la traduction automatique (TA ou machine translation, MT)
Système expert : limité par des grammaires complexes, questions de pragmatique et d’idiomaticité.
- Traduction directe “mot à mot”
- Par transfert : correspondance syntaxique
- Traduction interlangue : arbre syntaxique, paire de langue. Ex : Apertium (Citation: Corbı́-Bellot & al., 2005) Corbı́-Bellot, A., Forcada, M., Ortiz-Rojas, S., Pérez-Ortiz, J., Ramı́rez-Sánchez, G., Sánchez-Martı́nez, F., Alegria, I., Mayor, A. & Sarasola, K. (2005). An open-source shallow-transfer machine translation engine for the romance languages of Spain.
Systèmes inductifs ou approches data-driven : D’abord des classifieurs pour prédire le mots le plus probable dans une classe (préposition), puis statistical machine translation (SMT) dans les années 2010.
Alignement d’un corpus parallèle (fonctionne sur une paire de langue) : cooccurrences et tables de phrases. Exemple : Moses
Puis particulièrement Neural machine translation (NMT) depuis 2014 seq2seq puis Transformers
(Citation: Vaswani
& al.,
2017)
Vaswani,
A.,
Shazeer,
N.,
Parmar,
N.,
Uszkoreit,
J.,
Jones,
L.,
Gomez,
A.,
Kaiser,
L. & Polosukhin,
I.
(2017).
Attention Is All You Need.
https://doi.org/10.48550/arXiv.1706.03762
La NMT : encodage d’un corpus dans les deux langues dans un espace vectoriel continu. Entraînement d’un modèle spécialisé pour la traduction sur des paires de phrases. Puis encodage de la phrase source et décodage dans la langue cible. Exemple : Google Traduction, DeepL.
Source : @wangComprehensiveSurveyGrammar2020; @bryantGrammaticalErrorCorrection2023
Traduction automatique et LLMs
Un grand modèle de langue positionne chaque mot dans un espace vectoriel lors de sa phase d’apprentissage initiale à partir d’un grand volume de données en langue naturelle.
Afin de donner une réponse le LLM (GPT, Mistral, Qwen, Llama etc.) situe la requête utilisateur dans son espace vectoriel et sélectionne les tokens les plus probables à partir du contexte donné (la requête utilisateur ou prompt et les tokens qu’il a déjà généré).
Les LLMs sont donc généralistes, ils ne sont pas destinés à la traduction plus qu’à la correction d’erreurs grammaticales ou à l’écriture créative.
LLM vs NMT pour la Traduction automatique
NMT : traduction plus littérale, modèle spécialisé.
LLM : traduction plus idiomatique, tendance à la confabulation.
« Furthermore, our frequency analysis of PoS tags reveals that LLMs align more closely with HT in their usage, especially in terms of adverbs, and auxiliary verbs, while NMT models tend to overproduce specific tags in shorter sentences. This suggests that LLMs, although not perfect, are making strides in mimicking human translation patterns. » (Citation: Sizov & al., 2024) Sizov, F., España-Bonet, C., Van Genabith, J., Xie, R. & Dutta Chowdhury, K. (2024). Analysing Translation Artifacts: A Comparative Study of LLMs, NMTs, and Human Translations. Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.wmt-1.116
La fin de la NMT?
« What’s more, IBM announced the deprecation of Watson Language Translator, its NMT service, encouraging users to migrate to — guess what? — WatsonX LLMs. This move establishes IBM as one of the first tech giants to sunset its NMT efforts and focus on LLMs for automated translation purposes. » (Citation: Ciesielski, 2024) Ciesielski, J. (2024). Neural Machine Translation Versus Large Language Models. Consulté à l’adresse https://multilingual.com/magazine/june-2024/neural-machine-translation-versus-large-language-models/
Le futur de la traduction automatique
We anticipate that, soon, LLMs will become a viable enterprise solution for translation. This will likely come when we move towards task-specific LLMs trained specifically for translation. These models will be smaller and more practical to deploy and maintain than today’s massive foundational models. (Citation: Ciesielski, 2024) Ciesielski, J. (2024). Neural Machine Translation Versus Large Language Models. Consulté à l’adresse https://multilingual.com/magazine/june-2024/neural-machine-translation-versus-large-language-models/
Les LLMs font la traduction et l’évaluation de la traduction.
Question d’évaluation
La traduction automatique : score BLEU (comparaison de la phrase traduite avec un référentiel de phrases bien traduites, score de proximité), WER (calcul du nombre de mot mal ou non traduit), METEOR etc.
La Grammar Error Correction (GEC) compare la phrase source (avec erreurs), la phrase corrigée et une phrase de référence (la ground truth ou le gold standard donnée par un humain). Cette approche demande un corpus annoté en reference.
Métriques traditionnelles de GEC
- Edit-Based Metrics :
- M² (MaxMatch) : On aligne les phrases corrigées par le système avec celles de référence, puis on extrait les “edits” (opérations de correction : insertion, suppression, remplacement). On calcule précision, rappel, F0.5(donc précision pondérée deux fois plus que rappel).
- ERRANT (Error Annotation Toolkit): alignement de l’hypothèse avec la phrase source et la phrase cible et classification du type d’erreur (morphologie, orthographe, syntaxe).
- Sentence-Based metrics:
- GLEU (grammar-aware BLEU) : comparaison de n-grammes.
Ces mesures reposent sur l’alignement entre une hypothèse et une référence figée.
Mesure de la correction sans référence
Les métriques basées sur un corpus de référence limitent la correction a une forme seulement.
Mesure sans référence (Citation: Napoles & al., 2016) Napoles, C., Sakaguchi, K. & Tetreault, J. (2016). There’s No Comparison: Reference-less Evaluation Metrics in Grammatical Error Correction. Association for Computational Linguistics. https://doi.org/10.18653/v1/D16-1228 : comparaison directe de la phrase source (avec erreurs) et de la phrase corrigée avec un LLM.
Méthodes d’évaluation avec un LLM:
- Proximité/distance : Comparaison des vecteurs de la phrase source et celles de la phrase corrigée.
- Perplexité/log-probabilité : plus une phrase est fluide plus elle est probable (donc correcte).
- Spécialisation d’un LLM pour l’évaluation : Machine learning sur un corpus annoté avec des scores attribué ex: SOME (Citation: Yoshimura & al., 2020) Yoshimura, R., Kaneko, M., Kajiwara, T. & Komachi, M. (2020). SOME: Reference-less Sub-Metrics Optimized for Manual Evaluations of Grammatical Error Correction. International Committee on Computational Linguistics. https://doi.org/10.18653/v1/2020.coling-main.573
- LLM as judges : instruction en langues naturelles.
« The decrease in correlation as the LLM scale decreases, such as with Llama 2 and GPT-3.5, suggests the importance of the LLM scale. Especially, the decrease in correlation when adding fluent corrected sentences (“+ Fluent corr.”) compared to “Base” implies that smaller-scale LLMs may not adequately consider the fluency of sentences. Possible reasons for this include issues such as LLM’s tendency to produce the same scores (Appendix C) and the inability to interpret the context of prompts as expected by users. However, GPT-4 consistently demonstrated a high correlation and provided more stable evaluations compared to traditional metrics. » (Citation: Kobayashi & al., 2024) Kobayashi, M., Mita, M. & Komachi, M. (2024). Large Language Models Are State-of-the-Art Evaluator for Grammatical Error Correction. https://doi.org/10.48550/arXiv.2403.17540
Les LLM-as-judge signifie que non seulement la correction est effectuée par le LLM mais cette correction est aussi évaluée par le LLM lui-même.
Les limites des LLMs pour la GEC
- Les LLMs sont probabilistes : question de reproductibilité et d’interprétabilité
- Fluidité et grande probabilité = grammaticalité ?
- Favorise les langues bien dotées. Ex Bengali (Citation: Maity & al., 2024) Maity, S., Deroy, A. & Sarkar, S. (2024). How Ready Are Generative Pre-trained Large Language Models for Explaining Bengali Grammatical Errors?. https://doi.org/10.48550/arXiv.2406.00039
(et limites de l’utilisation de LLM pour évaluer d’autres LLMs : biais favorable du LLM pour ses propres productions (Citation: Wataoka & al., 2025) Wataoka, K., Takahashi, T. & Ri, R. (2025). Self-Preference Bias in LLM-as-a-Judge. https://doi.org/10.48550/arXiv.2410.21819 )
Changement de paradigme
Avant les LLM, les outils de ‘corrections’ sont spécialisés pour la correction ortho-typographique. Maintenant les outils de correction dépassent les limites de la simple correction grammaticale.
- Reformulation.
- Génération de texte.
- Masquer l’utilisation d’une IA.
Quels enjeux ?
Quelle valeur on accorde au travail de relecture et correction ?
Si écrire c’est avant tout réécrire : que signifie déléguer la (re)formulation à un LLM ?
Un gain de temps ?
Une déprise du texte ?
Homogénéisation de la langue
Mouvement de standardisation de la langue reposant sur une sur-norme « légitimée et maintenue par tout un édifice de croyances sur la nature de la langue et sur ce qui est correct ou incorrect, croyances qui sont dictées inévitablement par les valeurs sociales et esthétiques de la société concernée. » (Citation: Lodge, 1993) Lodge, R. (1993). French, from dialect to standard. London ; New York : Routledge.
- Problématique de l’« approche par défaut » (Citation: Paschalidis, 2025) Paschalidis, A. (2025). Vers un langage sans relief ? L’impact de l’IA sur nos mots.
- Prépondérance des données standardisées voire générées par des LLMs dans les données d’entraînement (Citation: Shumailov & al., 2024) Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R. & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature, 631(8022). 755–759. https://doi.org/10.1038/s41586-024-07566-y et (Citation: Guo & al., 2024) Guo, Y., Shang, G., Vazirgiannis, M. & Clavel, C. (2024). The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text. https://doi.org/10.48550/arXiv.2311.09807 .
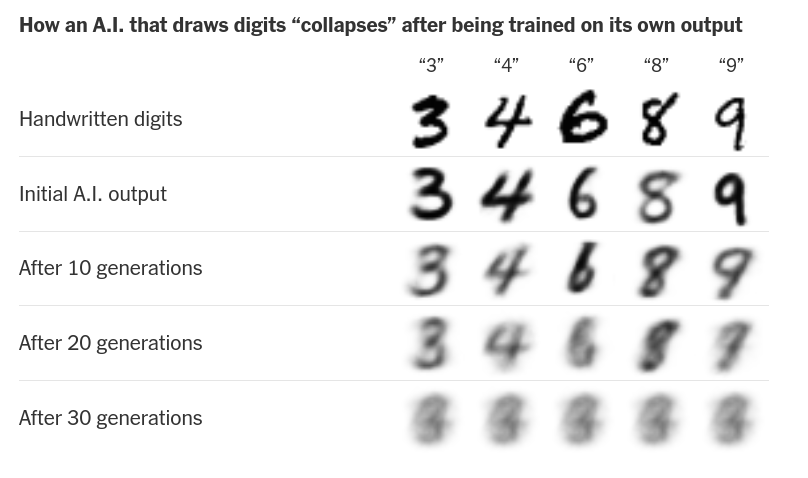
Effondrement du modèle après entrainement sur ses propres sorties

Perte de diversité après entraînement sur des données synthétiques
- Un idéal de clarté qui finit par s’auto-parodier (le fameux style chatgpt)
We show that while the core content of texts is retained when LLMs polish and rewrite texts, not only do they homogenize writing styles, but they also alter stylistic elements in a way that selectively amplifies certain dominant characteristics or biases while suppressing others - emphasizing conformity over individuality. By varying LLMs, prompts, classifiers, and contexts, we show that these trends are robust and consistent. (Citation: Sourati & al., 2025) Sourati, Z., Karimi-Malekabadi, F., Ozcan, M., McDaniel, C., Ziabari, A., Trager, J., Tak, A., Chen, M., Morstatter, F. & Dehghani, M. (2025). The shrinking landscape of linguistic diversity in the age of large language models. Consulté à l’adresse https://arxiv.org/abs/2502.11266
Des compétences poussées en ingénierie de prompts sont nécessaires pour contourner les effets liés aux approches par défaut. Cependant, même avec l’expertise requise, les LLMs ont tendance à générer des réponses inexactes ou inventées, à revenir à leurs réglages par défaut, rendant les reformulations successives presque inévitables, parfois jusqu’à provoquer un effondrement du modèle. Par conséquent, cette « attraction par défaut » devient un paramètre dont il faut systématiquement tenir compte. (Citation: Paschalidis, 2025) Paschalidis, A. (2025). Vers un langage sans relief ? L’impact de l’IA sur nos mots.
Si une formulation est fortement présente dans le corpus d’entraînement est-ce que c’est nécessairement la meilleure ? L’approche par défaut vaut-elle pour tous les contextes ?
La rédaction académique : déprise du texte, déprise du sens ?
- Tension entre rapidité et standards exigeants
- Pouvoir rédiger dans un style “natif” même dans une langue étrangère
Existe-t-il un seuil, une limite, au-delà de laquelle le recours aux LLMs constitue une perte de maîtrise du texte ?
Dire la même chose avec des mots différents change-t-il le sens ?
L’alignement des valeurs et le système de valeurs
« The problem of achieving agreement between our true preferences and the objective we put into the machine is called the value alignment problem: the values or objectives put into Value alignment problem the machine must be aligned with those of the human. » (Citation: Russell & al., 2022) Russell, S. & Norvig, P. (2022). Artificial intelligence: a modern approach (Fourth edition, global edition). Pearson.
L’intelligence humaine commence là où celle de la machine s’arrête. Si on découvre de nouvelles capacités à la machine alors on enlève cette capicité de la définition de l’intelligence humaine. « More than fifteen years ago Hilary Putnam identified the old problem we face to this day: ‘The question that won’t go away is how much what we call intelligence presupposes the rest of human nature’ (1988) » (Citation: McCarty, 2005) McCarty, W. (2005). Humanities Computing (Paperback edition). Palgrave Macmillan.
Autrement dit, si on laisse à la machine cette tâche c’est qu’on tend à l’estimer comme peu valorisante dans notre système de valeur actuel.
Alors que éviter les fautes d’orthographes devient de plus en plus facile, est-ce qu’on devient plus indulgents ?
Des ‘petites’ corrections finales ?
Currently, academic publishers only allow the use of ChatGPT and similar tools to improve the readability and language of research articles. However, the ethical boundaries and acceptable usage of AI in academic writing are still undefined, and neither humans nor AI detection tools can reliably identify text generated by AI (Citation: Homolak, 2023) Homolak, J. (2023). Exploring the adoption of ChatGPT in academic publishing: insights and lessons for scientific writing. Croatian Medical Journal, 64(3). 205–207. https://doi.org/10.3325/cmj.2023.64.205
It is being increasingly observed that content generated by ChatGPT is going undeclared and undetected, resulting in its appearance in articles published in scholarly journals. […] The general policy among publishers states that AI tools must not be used to create, alter or manipulate original research data and results (Elsevier., 2023; Roche, 2024). (Citation: Strzelecki, 2025) Strzelecki, A. (2025). ‘As of my last knowledge update’: How is content generated by ChatGPT infiltrating scientific papers published in premier journals?. Learned Publishing, 38(1). e1650. https://doi.org/10.1002/leap.1650
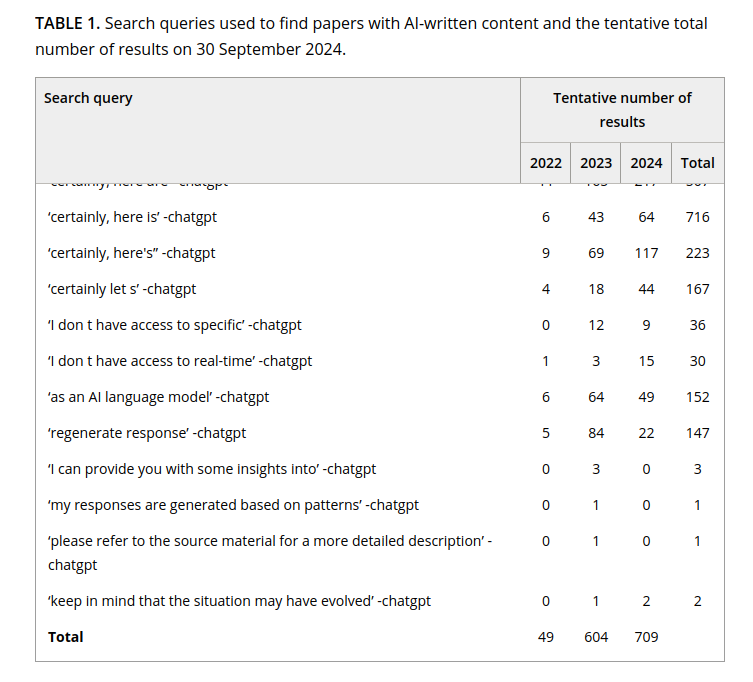
Articles contenant des réponses de prompts
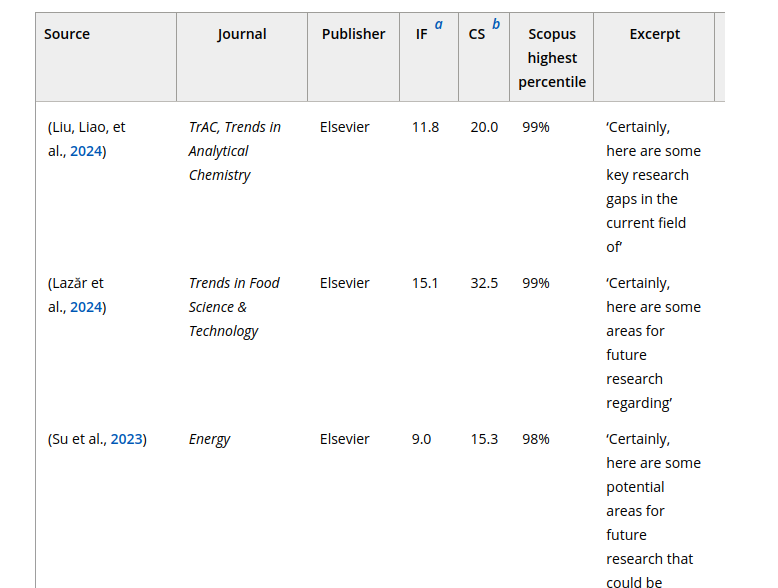
Articles contenant des réponses explicites de ChatGPT
Est-ce que négliger la correction revient à négliger la lecture et l’écriture ?
Effet nivelant et influence de la machine
Les moins bons traducteurs sont aidés par la TA mais les meilleurs traducteurs sont désavantagés par la TA. Effet limitant car tendance à se laisser influencer : réduction des intuitions de traduction et de la créativité traductionnelle. (Citation: Schumacher, 2023) Schumacher, P. (2023). La post-édition de traduction automatique en contexte d’apprentissage. Universite de Liege.
Une influence pas négligeable : même quand un.e participant.e n’a plus les recommandations de la machine, iel reproduit les erreurs des recommandations (Citation: Vicente & al., 2023) Vicente, L. & Matute, H. (2023). Humans inherit artificial intelligence biases. Scientific Reports, 13(1). 15737. https://doi.org/10.1038/s41598-023-42384-8 : délégation cognitive ou cognitive offloading
Est-ce que vous avez l’impression, quand vous utilisez un LLM, que sa production est meilleure que la vôtre ? Est-ce que vous avez l’impression que même dans les cas où vous ne vous en servez pas/plus vous continuez à utiliser son vocabulaire ?
Quelle est l’autorité de la machine ?
Quelques outils
Outils généralistes
LLMs non spécialisé : ChatGPT, Mistral, Llama, Claude etc., modèles téléchargés localement (ollama).
Tenir compte des biais du modèle et de son interaction avec lui.
L’effet ‘AI-powered’
La correction automatique existe avant ChatGPT et les LLM offraient des techniques poussées de GEC mais il fallait encore que de nouveaux usages s’ancrent et qu’il y ait un intérêt économique à maintenir l’utilisateur sur la même plateforme d’où l’intégration de LLM dans l’outil.
Outils spécialisés
Les outils historiques (francophones)
Sources sur les technologies d’Antidotes :
Reformulation et IA (décembre 2023)
[ChatGPT peut-il remplacer Antidote ?](août 2025)(https://www.antidote.info/fr/blogue/astuces-et-conseils/chatgpt-peutil-remplacer-antidote)
Une combinaison d’outils spécialisés et utilisant des techniques diverses.
ProLexis (pas de vidéos youtube depuis 3 ans, ProLexis7) Outil professionel, analyseur syntaxique, interface à l’ancienne, powerpoint à l’ancienne.
Les nouveaux outils
EditPad : AI detector, humanize AI text, Plagiarim checker, paraphrasing tool, story generator, text summarizer, AI essay writer etc. Probablement juste ChatGPT hooked à une interface avec un system-prompt. Apparamment mauvais according to @bordalejoScarletCloakForest2025
Screenshot Editpad
Corriger = masquer que le texte ne vient pas d’une machine, ou chercher à le détecter?
Writefull: Title generator, Abstract generator, paraphraser, academizer.
Effet de mode = disparition et apparition de solutions miracles (down le 22 septembre, up le 30 septembre mais bug)
Grammarly donne une note à partir des critères de formalité, 4 niveaux : correctness (corrige erreurs grammaticales), clarity (reformulation) engagement (option payante), delivery (payant), plagiarism detection (payant). Option ‘generative AI’ avec des prompts pre-écrits qui restreignent l’usage. Et un browser plugin qui permet de s’en servir avec tous les sites google (docs, gmail, youtube comments).
improve est une option liée à “Generative AI” juste ‘améliorer’.
“Is QuillBot considered AI writing? 2 years ago Updated Everyone’s talking about AI writing these days, and debate over its use — and misuse — rages. QuillBot has helped you grow and improve as a writer, but you may wonder if using it is considered AI writing. Good question. The short answer is “no.” QuillBot’s tools have specific uses, such as correcting grammar or paraphrasing sentences. It’s up to you to use the feedback and suggestions to create content that is solely your own. ChatGPT and similar AI writers, on the other hand, can generate essay-length text from a few prompts. That writing can then be presented with no changes. Since QuillBot is not considered AI writing, most plagiarism checkers will not flag its use.
That said, we make no guarantees if someone uses QuillBot on text generated by a tool like ChatGPT. Why not play it safe and craft the content yourself? (With QuillBot’s help, of course!)
Intégration dans tous les autres outils
Prise de note :
Notion : génération de texte.
Evernote: RAG
Rédaction de mail etc.
Conclusion
À retenir
- La correction est un processus itératif qui implique une phase d’écriture, de lecture, d’annotation et de réécriture : l’IA a transformé ce paradigme à toutes les étapes.
- Les premiers correcteurs automatiques se sont concentrés sur la correction ortho-typographiques, avec les systèmes de GEC complexes depuis les années 2000 ces outils traitent de reformulation
- La Grammar Error Correction est une tâche voisine de la Traduction automatique : les technologies sous jacentes sont partagées
- L’évaluation de la GEC et de la TA fait écho aux processus d’évaluation propre à la correction par un humain.
- Avec l’ancrage de nouvelles pratiques discrètes de l’IA, on assiste à une nouvelle phase : la correction comme écriture et comme masquage de l’utilisation d’IA générative. Et l’intégration d’outils dit d’IA dans toutes les applications de traitement de texte etc.
- Les promesses de gain de temps et de productivité cachent des enjeux économiques forts : on ne peut que rester méfiants face aux biais de ces outils tout en prennant conscience de ses propres influences.
Prochaines séances
- Les systèmes d’exploitation le 6 novembre avec Louis-Olivier
- La Synthèse des sources et la recherche d’information le 15 janvier 2026.
Bibliographie
- Brossard (1924)
- Brossard, L. (1924). Correcteur typographe. Les règles typographiques / L. -E. Brossard.
- Ciesielski (2024)
- Ciesielski, J. (2024). Neural Machine Translation Versus Large Language Models. Consulté à l’adresse https://multilingual.com/magazine/june-2024/neural-machine-translation-versus-large-language-models/
- Corbı́-Bellot, Forcada, Ortiz-Rojas, Pérez-Ortiz, Ramı́rez-Sánchez, Sánchez-Martı́nez, Alegria, Mayor & Sarasola (2005)
- Corbı́-Bellot, A., Forcada, M., Ortiz-Rojas, S., Pérez-Ortiz, J., Ramı́rez-Sánchez, G., Sánchez-Martı́nez, F., Alegria, I., Mayor, A. & Sarasola, K. (2005). An open-source shallow-transfer machine translation engine for the romance languages of Spain.
- Derrida (2005)
- Derrida, J. (2005). Paper Machine. Stanford University Press.
- Guo, Shang, Vazirgiannis & Clavel (2024)
- Guo, Y., Shang, G., Vazirgiannis, M. & Clavel, C. (2024). The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text. https://doi.org/10.48550/arXiv.2311.09807
- Homolak (2023)
- Homolak, J. (2023). Exploring the adoption of ChatGPT in academic publishing: insights and lessons for scientific writing. Croatian Medical Journal, 64(3). 205–207. https://doi.org/10.3325/cmj.2023.64.205
- Kobayashi, Mita & Komachi (2024)
- Kobayashi, M., Mita, M. & Komachi, M. (2024). Large Language Models Are State-of-the-Art Evaluator for Grammatical Error Correction. https://doi.org/10.48550/arXiv.2403.17540
- Lodge (1993)
- Lodge, R. (1993). French, from dialect to standard. London ; New York : Routledge.
- Maity, Deroy & Sarkar (2024)
- Maity, S., Deroy, A. & Sarkar, S. (2024). How Ready Are Generative Pre-trained Large Language Models for Explaining Bengali Grammatical Errors?. https://doi.org/10.48550/arXiv.2406.00039
- McCarty (2005)
- McCarty, W. (2005). Humanities Computing (Paperback edition). Palgrave Macmillan.
- Napoles, Sakaguchi & Tetreault (2016)
- Napoles, C., Sakaguchi, K. & Tetreault, J. (2016). There’s No Comparison: Reference-less Evaluation Metrics in Grammatical Error Correction. Association for Computational Linguistics. https://doi.org/10.18653/v1/D16-1228
- Paschalidis (2025)
- Paschalidis, A. (2025). Vers un langage sans relief ? L’impact de l’IA sur nos mots.
- Russell & Norvig (2022)
- Russell, S. & Norvig, P. (2022). Artificial intelligence: a modern approach (Fourth edition, global edition). Pearson.
- Schumacher (2023)
- Schumacher, P. (2023). La post-édition de traduction automatique en contexte d’apprentissage. Universite de Liege.
- Shumailov, Shumaylov, Zhao, Papernot, Anderson & Gal (2024)
- Shumailov, I., Shumaylov, Z., Zhao, Y., Papernot, N., Anderson, R. & Gal, Y. (2024). AI models collapse when trained on recursively generated data. Nature, 631(8022). 755–759. https://doi.org/10.1038/s41586-024-07566-y
- Sizov, España-Bonet, Van Genabith, Xie & Dutta Chowdhury (2024)
- Sizov, F., España-Bonet, C., Van Genabith, J., Xie, R. & Dutta Chowdhury, K. (2024). Analysing Translation Artifacts: A Comparative Study of LLMs, NMTs, and Human Translations. Association for Computational Linguistics. https://doi.org/10.18653/v1/2024.wmt-1.116
- Sourati, Karimi-Malekabadi, Ozcan, McDaniel, Ziabari, Trager, Tak, Chen, Morstatter & Dehghani (2025)
- Sourati, Z., Karimi-Malekabadi, F., Ozcan, M., McDaniel, C., Ziabari, A., Trager, J., Tak, A., Chen, M., Morstatter, F. & Dehghani, M. (2025). The shrinking landscape of linguistic diversity in the age of large language models. Consulté à l’adresse https://arxiv.org/abs/2502.11266
- Strzelecki (2025)
- Strzelecki, A. (2025). ‘As of my last knowledge update’: How is content generated by ChatGPT infiltrating scientific papers published in premier journals?. Learned Publishing, 38(1). e1650. https://doi.org/10.1002/leap.1650
- Turing (1950)
- Turing, A. (1950). Computing Machinery and Intelligence. Mind, LIX(236). 433–460. https://doi.org/10.1093/mind/LIX.236.433
- Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser & Polosukhin (2017)
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A., Kaiser, L. & Polosukhin, I. (2017). Attention Is All You Need. https://doi.org/10.48550/arXiv.1706.03762
- Vicente & Matute (2023)
- Vicente, L. & Matute, H. (2023). Humans inherit artificial intelligence biases. Scientific Reports, 13(1). 15737. https://doi.org/10.1038/s41598-023-42384-8
- Vitali-Rosati (2025)
- Vitali-Rosati, M. (2025). Manifeste pour des Études Critiques de l’Intelligence Artificielle. Consulté à l’adresse http://blog.sens-public.org/marcellovitalirosati/manifeste-ecia.html
- Wataoka, Takahashi & Ri (2025)
- Wataoka, K., Takahashi, T. & Ri, R. (2025). Self-Preference Bias in LLM-as-a-Judge. https://doi.org/10.48550/arXiv.2410.21819
- Yoshimura, Kaneko, Kajiwara & Komachi (2020)
- Yoshimura, R., Kaneko, M., Kajiwara, T. & Komachi, M. (2020). SOME: Reference-less Sub-Metrics Optimized for Manual Evaluations of Grammatical Error Correction. International Committee on Computational Linguistics. https://doi.org/10.18653/v1/2020.coling-main.573