Débogue tes humanités
Synthèse des sources et Recherche d'Information
# Programme de la séance
- Introduction et rappels
- Les systèmes complexes intégrant de l’IA: les agents IA
- le RAG
- RAG et applications généralistes
- Les Assistants de recherche ‘AI powered’
# Présentation et objectif des ateliers
Format : 4 séances de 2heures, sans inscription, participation libre (à justifier pour le certificat des Humanités Numériques)
Objectifs de la série d’atelier :
- Comprendre les fondamentaux de l’IA et de son histoire
- Obtenir des notions critiques sur le fonctionnement profond des outils
- Cerner les enjeux actuels sur des thématiques qui affectent la recherche et l’enseignement
# Certificat canadien en Humanités Numériques

Certificat canadien en Humanités Numériques

# Les fondamentaux : rappels
# Qu’est ce que l’IA ?
Des programmes informatiques que nous estimons à la hauteur de l’intelligence humaine ? Le développement des technologies fait évoluer cette définition de l’intelligence non seulement artificielle mais aussi humaine.
‘IA’ depuis 5 ans, a remplacé le ’numérique’ des années 2010, et le ‘cyberespace’ des années 1990 et 2000. (Citation: Vitali-Rosati, 2025) Vitali-Rosati, M. (2025). Manifeste pour des Études Critiques de l’Intelligence Artificielle. Consulté à l’adresse http://blog.sens-public.org/marcellovitalirosati/manifeste-ecia.html .
Définition pratique pour ces ateliers: « un programme informatique qui effectue une prédiction. »
# Rappels : histoire de la discipline
- L’IA n’est pas une nouvelle discipline (terme de 1956 lors de la Dartmouth Summer Research Project on Artificial Intelligence par Marvin Minsky et John McCarthy).
- L’article Computing Machinery and Intelligence de (Citation: Turing, 1950) Turing, A. (1950). Computing Machinery and Intelligence. Mind, LIX(236). 433–460. https://doi.org/10.1093/mind/LIX.236.433 a orienté la discipline vers la création de chatbots.
- Les ‘saisons de l’IA’ suivent des phases d’approbation publique et de désintérêt pour le terme et les technologies associées.
- Changement de paradigmes actuels : de l’outil qui assiste à l’outil qui produit à l’outil qui trompe (correction orthotypo -> reformulation -> génération -> masquage de son utilisation).
- Ce qu’on fait entrer dans la catégorie d’« intelligent » a changé : le calcul savant est-il moins intelligent que le bavardage ?
# Rappels : IA symbolique / IA connexionniste
- Deux grandes approches en IA : une approche déductive (IA symbolique, système expert) vs. approche inductive (IA connexionniste, modèle de langue basé sur des plongements de mots ou embeddings = vecteurs).
- Un LLM (large language model) est la modélisation sous forme de vecteurs de chaque élément d’un très grand corpus (token ~mot) par rapport à cet ensemble.
- Un système expert peut être aussi complexe et énergivore qu’un LLM.
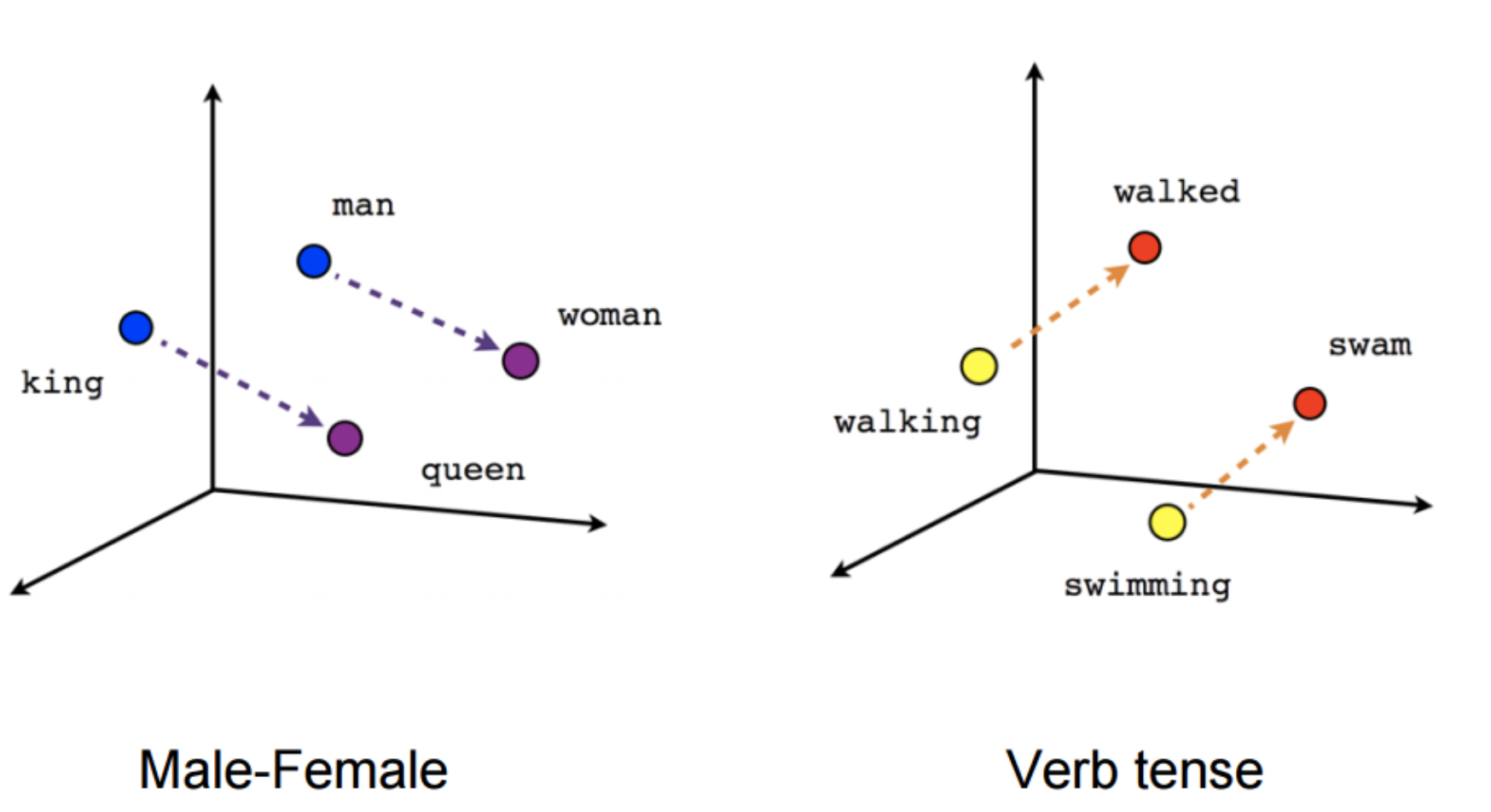
Plongements lexicaux ou word embeddings
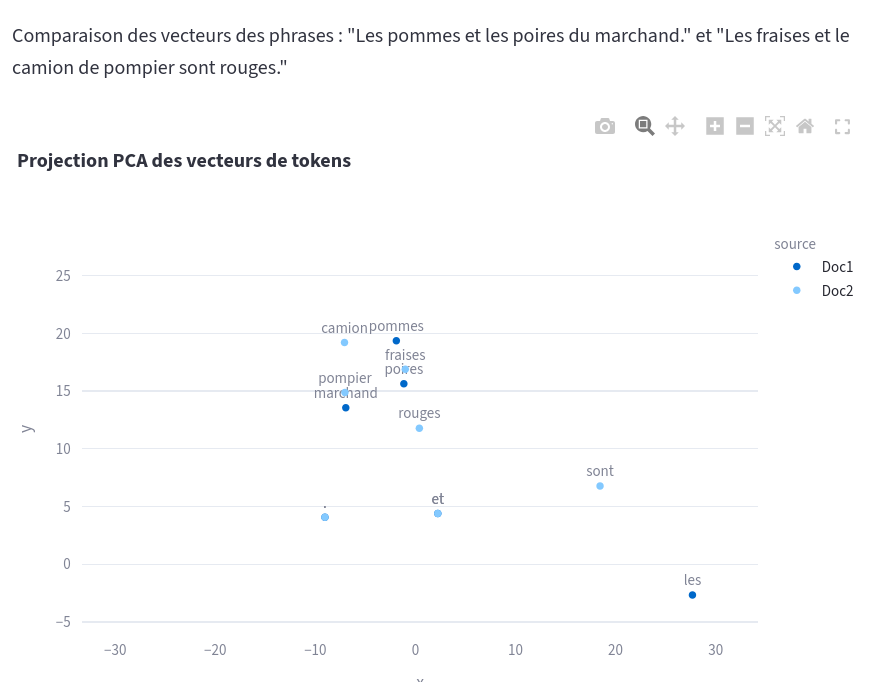
Comparaison de vecteurs dans un espace à deux dimensions
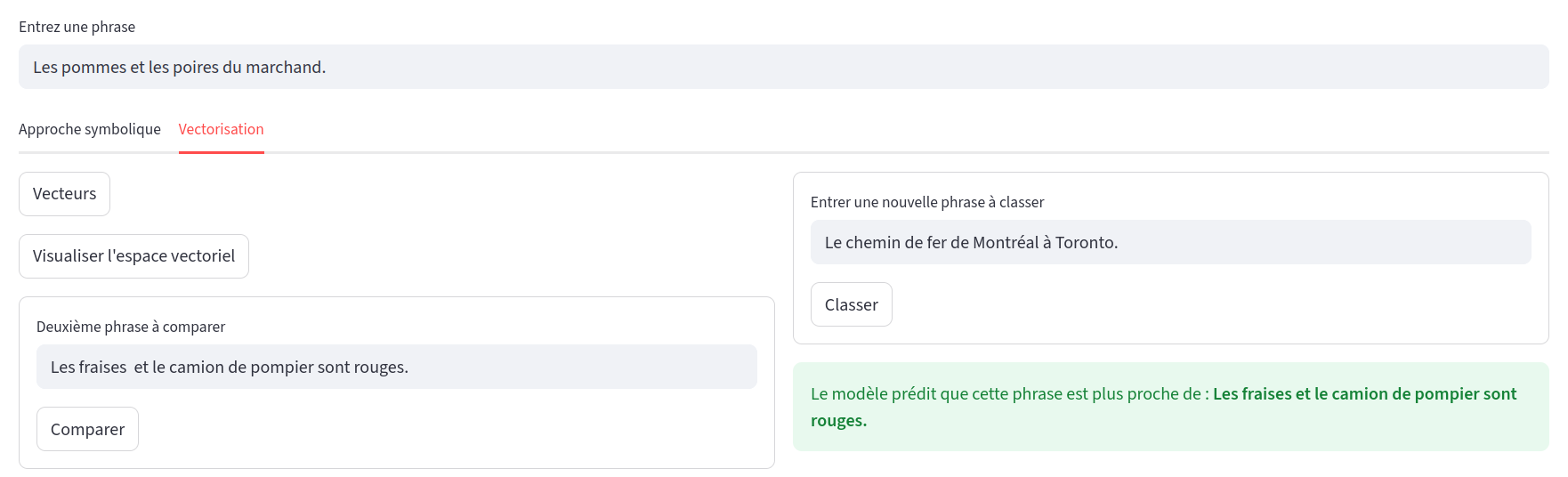
Classification avec algorithme K-Nearest-Neighbor d’une troisième phrase
# Rappel sur les LLMs
- Chatbots type ChatGPT, Mistral, Gemini, Claude etc. = application qui utilise un LLM (la représentation figée de la langue en vecteurs) pour faire de la prédiction de tokens (génération).
- Absence de référent ou de règle : probabilité pure -> plausible et convaincant.
- Les hallucinations =/= anomalies
- Les outils reflètent les intérêts et la vision du monde de ceux qui les concoivent: correcteurs orthographiques et grammaticaux incarnent une vision du monde centrée sur la productivité et la rapidité.
- Exploitation des capacités inductives d’un LLM ne dépend pas d’une interface en langue naturelle. Ex : classification avec de l’apprentissage machine (machine learning).
# Des systèmes d’IA complexes
# Quelle complexité ?
IA, dite générative ou d’automatisation de la prédiction de token, effectue aujourd’hui des tâches complexes à deux niveaux:
-
interprétation d’une instruction donnée en langue naturelle (avec son lot d’ambiguïté).
-
intégration de LLM dans des process ou pipelines qui impliquent des interactions en chaînes:
- Systèmes agentiques « agentic AI »
- RAG
# Exemple de système d’IA complexe: les agents
Un agent est une série d’appels à un LLM : l’agent est ce qui permet d’enchaîner input et output jusqu’à complétion d’une tâche. Le résultat de ces interactions peut ne pas être une réponse en langue naturelle ex: activation d’une fonction.
Autrement dit, un agent est une « IA » qui se répond à elle-même.
On parlera de système agentique quand plusieurs agents interagissent.
Démonstration d’un agent : assistant à l’exploration et la création de note sur un tableau interactif de (Citation: Arawjo, 2026) Arawjo, I. (2026). ianarawjo/splat. Consulté à l’adresse https://github.com/ianarawjo/splat
# Définition hypée des IA agentiques

Description des IA agentiques par Docker
# Description pas hypée de l’agent conversationnel de la démo
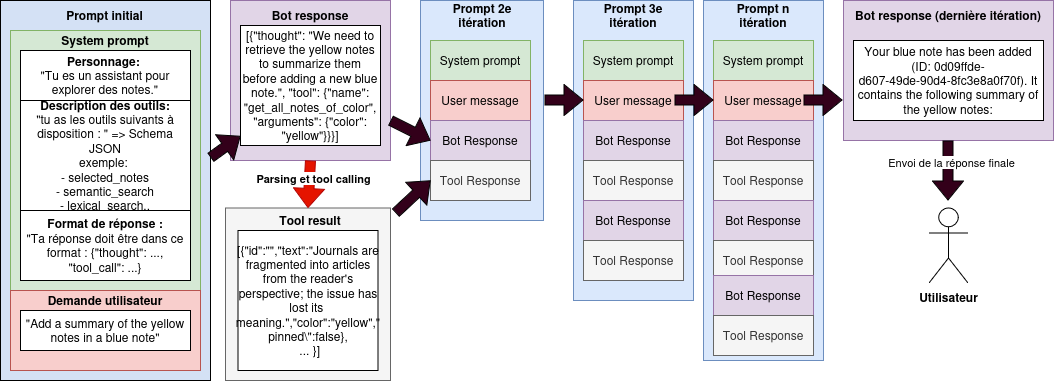
# Applications de chat actuelles
Depuis GPT-3.5 et sa sortie publique en décembre 2022, l’application ChatGPT ne se contente pas d’envoyer seul le prompt de l’utilisateur pour interroger le LLM: dans le prompt global, on trouve un ensemble d’instructions préliminaires (le system prompt) et d’informations complémentaires comme l’historique des échanges (chat history).
Depuis décembre 2024, le Model Context Protocol (MCP) permet l’intégration modulaire de l’interface de chat à d’autres fonctionalités.
![Le MCP[^mcp]](/images/mcp.png)
Le MCP[^mcp]
Exemple : la fonction search => RAG
# Recherche d’information et synthèse des sources
# Retrieval Augmented Generation
Limites du LLM:
- représentation figée sur les données d’entraînement (= mémoire implicite ne peut pas être mise à jour)
- fenêtre contextuelle limitée (ajd jusque 120 000 tokens, en réalité déclin après ~30 000 tokens)
-> perte de fiabilité
Le RAG : architecture de système d’IA qui repose sur une base de connaissance externe dans le but d’améliorer les réponses d’une IA générative sans demander d’entrainement supplémentaire (fine tuning). (Citation: Lewis & al., 2021) Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S. & Kiela, D. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. https://doi.org/10.48550/arXiv.2005.11401 (Facebook, University College London, New York University)
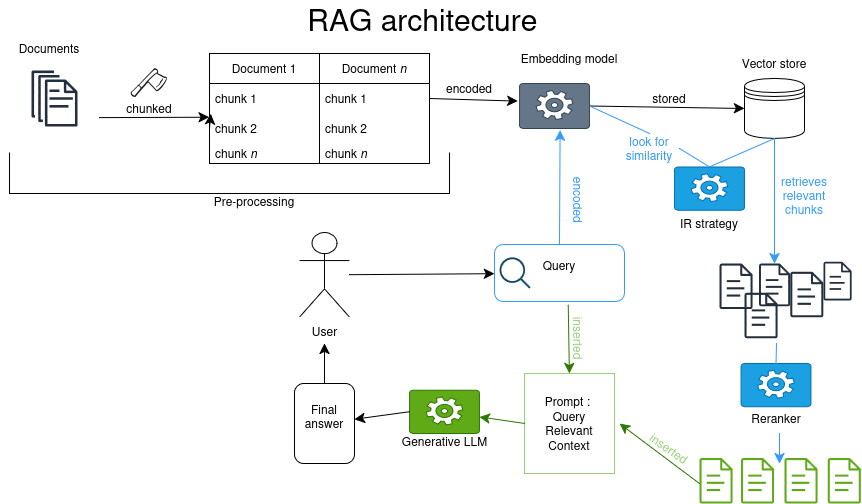
Superbe diagramme d’un RAG
# RAG en bref
Requête d’une base de données1 avec des méthodes de Recherche d’Information (TF-iDF ou similarité cosinus) + intégration des morceaux extraits au prompt. Le LLM effectue une synthèse. Ex: NotebookLM
# Points d’attention sur le RAG
- Jeux de données externes peut aussi être biaisé,
- Ajout de couches d’interprétation,
- Dissémination de l’information quand l’information se trouve dans plusieurs chunks,
- Angles morts quand l’information importante est dans un chunk non extrait.
# RAG des applications de chat généralistes
# Exemple: ChatGPT
We collaborated extensively with the news industry and carefully listened to feedback from our global publisher partners, including Associated Press, Axel Springer, Condé Nast, Dotdash Meredith, Financial Times, GEDI, Hearst, Le Monde, News Corp, Prisa (El País), Reuters, The Atlantic, Time, and Vox Media. Any website or publisher can choose to appear(opens in a new window) in ChatGPT search. If you’d like to share feedback, please email us at publishers-feedback@openai.com. — (Citation: , 2024) (2024). Introducing ChatGPT search. Consulté à l’adresse https://openai.com/index/introducing-chatgpt-search/
- Reformulation de l’entrée utilisateur en une ou plusieurs requêtes
- Requêtes envoyées à Bing et Shopify2 et sur leur base de données interne (médias partenaires).
- Re-ranking ?
- Réponse généré depuis le prompt contenant les informations extraites (+ system prompt, chat history etc.)
-> Atlas, un navigateur avec chatGPT comme « moteur de recherche » par défaut. (Citation: Dash, 2025) Dash, A. (2025). ChatGPT’s Atlas: The Browser That’s Anti-Web - Anil Dash. Consulté à l’adresse https://anildash.com/2025/10/22/atlas-anti-web-browser/ parle d’un navigateur ‘anti-web’:
- ne retourne pas de réponse sur le web.
- basé sur une interprétation de l’intention utilisateur vs. GUI
- autorise OpenAI à lire toutes les données lues et entrées dans le navigateur : « The idea is that ChatGPT will be your agent, but in reality you are ChatGPT’s agent »
By keeping the ChatGPT sidebar open while you browse, and giving it permission to look over your shoulder, OpenAI can suddenly access all kinds of things on the internet that they could never get to on their own.
# Exemple: Le Chat de Mistral
Partenariat avec l’AFP depuis janvier 2025 (Citation: , 2025) (2025). AFP and Mistral AI announce global partnership to enhance AI responses with reliable news content | AFP.com. Consulté à l’adresse https://www.afp.com/en/agency/inside-afp/press-release/afp-and-mistral-ai-announce-global-partnership-enhance-ai-responses . Opacité quant à la méthode de recherche d’information sur internet3.
# Assistants de recherche AI
# Qui ? quoi ?
- Google Scholar
- SemanticScholar
- JSTOR
- Primo Research Assistant (spécialisé bibliothèque)
- Web of Science Research Assistant
- Scopus AI
- Asta
- scite.ai
- undermind.ai
Qu’est-ce qu’on entend par IA dans ce cas ?
5 à 6 niveaux d’intervention possible !
# Création de métadonnées
Désambiguisation, keywords, classification de topics, abstract. (OpenAlex, Isidore? -> ML pour attribution de sujets reliés).
# Expansion de requête
-
Méthodes sans IA : thésaurus, ontologies.
-
Query expansion avec un LLM: « Écrit 10 variants de la requête suivantes »
# Méthodes de Recherche d’information
-
Méthodes classiques (non IA ?):
- recherche exacte4 avec opérateurs booléens: ex: ‘citation’ retourne ‘The decrease in uncited articles and its effect on the concentration of citations’
- recherche lexicale statistique: TF-iDF (term frequency inverse document frequency) et BM25 -> ranking de la recherche terme par rapport à sa présence dans le corpus.
- ex: SemanticScholar, Isidore
-
Recherche sémantique (semantic search/dense retrieval) utilisation des plongements lexicaux de modèles types encodeur (BERT) ou décodeur (e.g. GPT) lors de la recherche: représentation vectorielle de la requête et de l’entièreté de la base de données -> mesure de similarité cosinus.
- ex: fonction « Semantic Results » de JSTOR
-
Recherche hybride (hybrid search): mélange de 1. et 2. (pas forcément 50/50).
-> Impact sur la manière de requêter: 1. par mot-clé, 2. ’en langue naturelle’.
# Reranking
Classement des articles présentés selon un critère de pertinence par rapport à la requête.
-
ML classique (entraînement d’un modèle au classement)
-
Comparaison de vecteurs (requête/titre de l’article): score = proximité. ex: Primo search assistant5
-
Évaluation par un LLM type ‘gen AI’ : prompt de classement ou catégorisation de pertinence. Fournissent les explications: Ex: Asta
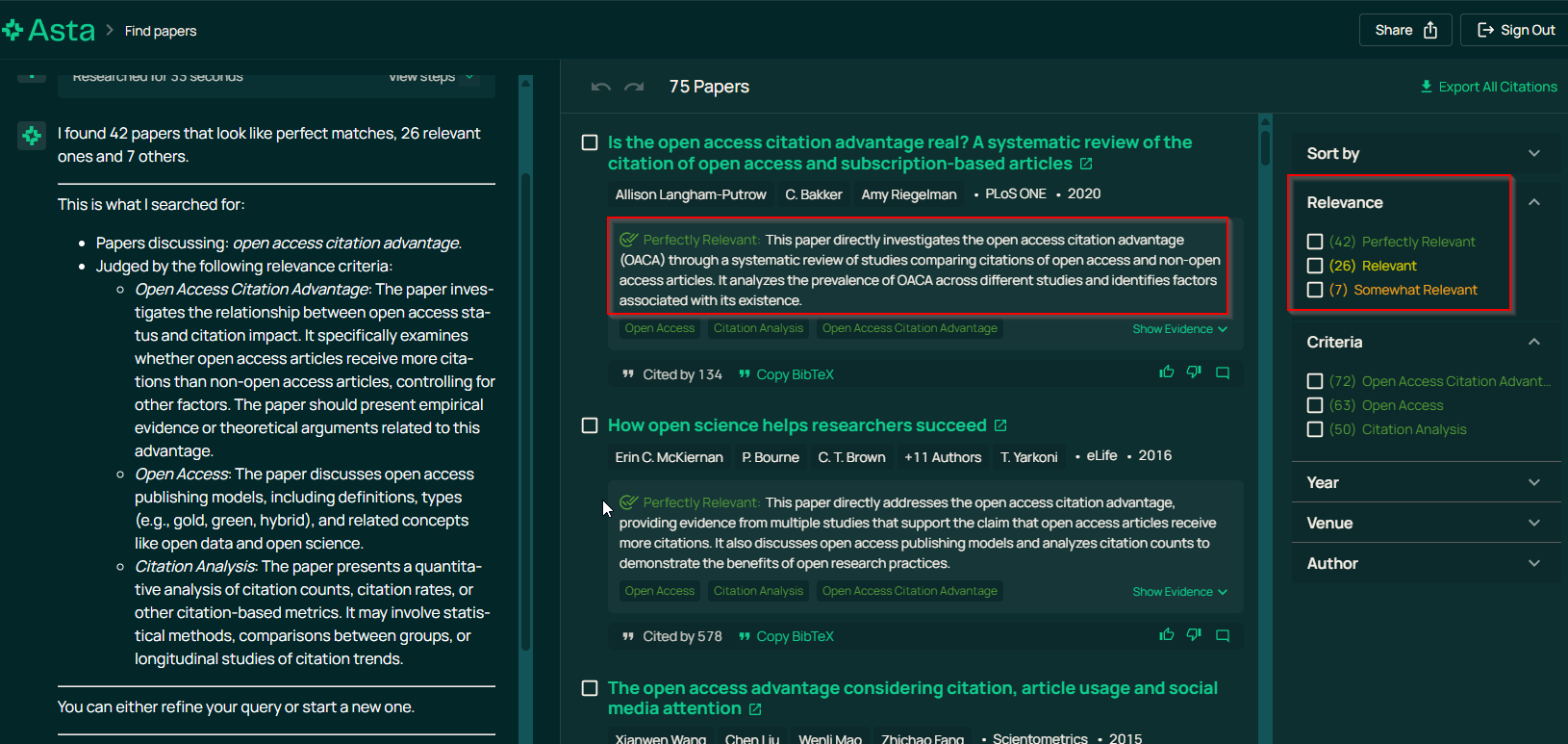
Asta présente la justification de la catégorie de pertinence
# Reranking (suite)
- Ajout de critères externes Ex: semantic Scholar, « highly-cited papers »
# Enrichissement de la liste de résultats

Google Scholar Labs donne une explication de la présence de l’article dans la liste de résultat
# Synthèse des articles ou assistant de revue de littérature
Synthèse des articles extraits pour répondre à une question en langue naturelle => RAG.
-
RAG simple: Elicit, SciSpace (source: Semantic Scolar, Open Alex), fonction TLDR de Semantic Scholar.
-
Deep research : Agentic AI, spécialisation de plusieurs agents, retourne un rapport complet en quelques minutes. Fonctionalités spécialisés Ex: Consensus fonctionalité « Study Snapchot ».
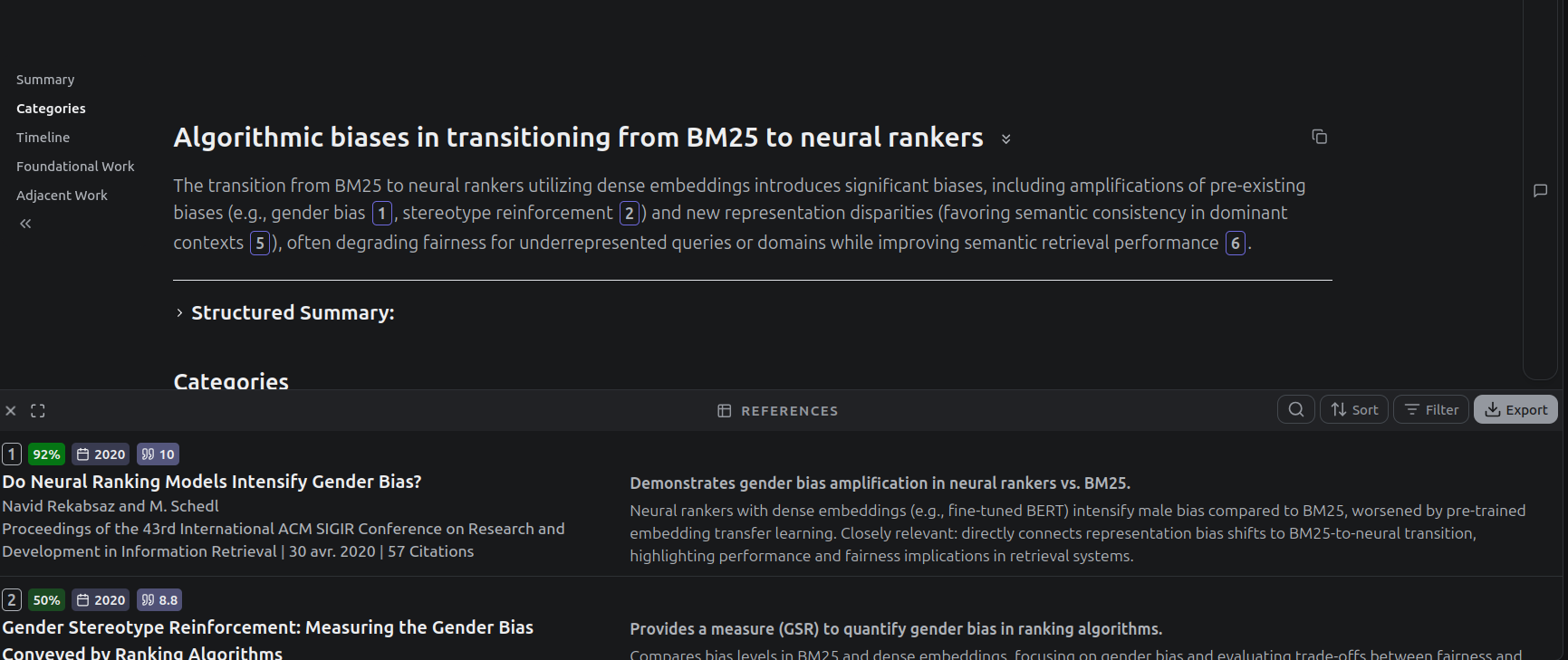
Undermind.ai
# Limites des outils de synthèse
- Quelles bases de données ?
- Basé sur métadonnées seulement (abstract)
- Peut inventer des sources pour répondre à une question (-> citogenesis phénomène qui précède les LLM et les lit review assistants.)
The AI-generated things get propagated into other real things, so students see them cited in real things and assume they’re real, and get confused as to why they lose points for using fake sources when other real sources use them (Citation: Klee, 2025) Klee, M. (2025). AI Is Inventing Academic Papers That Don’t Exist – And They’re Being Cited in Real Journals. Consulté à l’adresse https://www.rollingstone.com/culture/culture-features/ai-chatbot-journal-research-fake-citations-1235485484/
# Overview par Aaron Tay
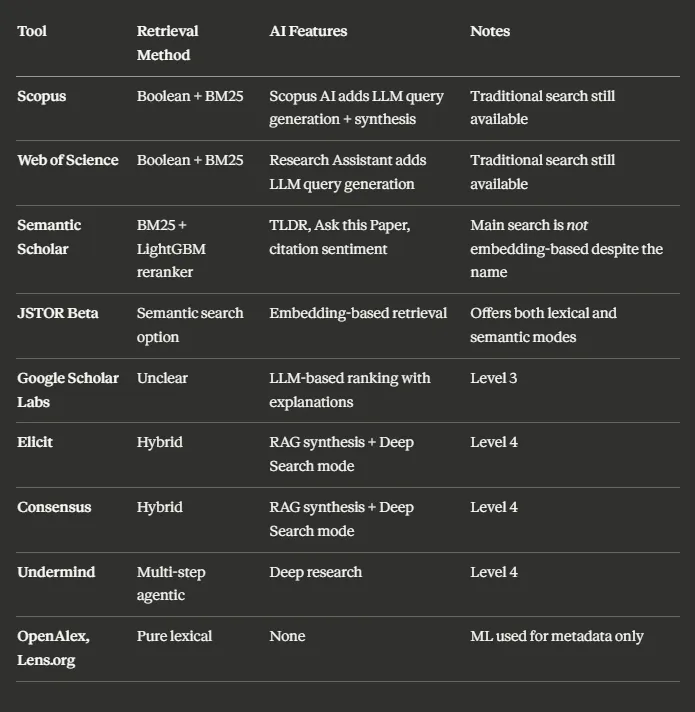
Synthèse des outils d’IA
Pour suivre ces questions, suivre Aaron Tay : https://aarontay.substack.com/ (Citation: Tay, 2025) Tay, A. (2025). What Do We Actually Mean by « AI-Powered Search »?. Consulté à l’adresse https://aarontay.substack.com/p/what-do-we-actually-mean-by-ai-powered
# Échanges et questions
# Prochains ateliers débogue
Le matériel informatique : trésor ou ordure ? 29 janvier, même heure même lieu
Rester à la fine pointe de la technologie, ça coûte cher. Mais est-ce même utile ? Est-ce que ça se fait de seulement remplacer la batterie de son ordinateur, ou un disque pour rendre sa machine plus rapide ? C’est souvent plus facile qu’on le pense ! Avec cette démo, on vous aide à garder votre machine plus longtemps, et votre argent dans vos poches !
Documentation des nouvelles pratiques liées à l’utilisation de l’IA : préconisations pour les SHS 12 mars, même heure même lieu
# Références
- (2025)
- (2025). AFP and Mistral AI announce global partnership to enhance AI responses with reliable news content | AFP.com. Consulté à l’adresse https://www.afp.com/en/agency/inside-afp/press-release/afp-and-mistral-ai-announce-global-partnership-enhance-ai-responses
- Arawjo (2026)
- Arawjo, I. (2026). ianarawjo/splat. Consulté à l’adresse https://github.com/ianarawjo/splat
- Bigendako & Syriani (2026)
- Bigendako, B. & Syriani, E. (2026). Modeling a Tool for Conducting Systematic Reviews Iteratively. Consulté à l’adresse https://www.scitepress.org/Link.aspx?doi=10.5220/0006664405520559
- Dash (2025)
- Dash, A. (2025). ChatGPT’s Atlas: The Browser That’s Anti-Web - Anil Dash. Consulté à l’adresse https://anildash.com/2025/10/22/atlas-anti-web-browser/
- Irwin & Xu (2025)
- Irwin, M. & Xu, Y. (2025). GenAI vs. Agentic AI: What Developers Need to Know. Consulté à l’adresse https://www.docker.com/blog/genai-vs-agentic-ai/
- Klee (2025)
- Klee, M. (2025). AI Is Inventing Academic Papers That Don’t Exist – And They’re Being Cited in Real Journals. Consulté à l’adresse https://www.rollingstone.com/culture/culture-features/ai-chatbot-journal-research-fake-citations-1235485484/
- Lewis, Perez, Piktus, Petroni, Karpukhin, Goyal, Küttler, Lewis, Yih, Rocktäschel, Riedel & Kiela (2021)
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W., Rocktäschel, T., Riedel, S. & Kiela, D. (2021). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. https://doi.org/10.48550/arXiv.2005.11401
- (2024)
- (2024). Introducing ChatGPT search. Consulté à l’adresse https://openai.com/index/introducing-chatgpt-search/
- Tay (2025)
- Tay, A. (2025). What Do We Actually Mean by « AI-Powered Search »?. Consulté à l’adresse https://aarontay.substack.com/p/what-do-we-actually-mean-by-ai-powered
- Turing (1950)
- Turing, A. (1950). Computing Machinery and Intelligence. Mind, LIX(236). 433–460. https://doi.org/10.1093/mind/LIX.236.433
- Vitali-Rosati (2025)
- Vitali-Rosati, M. (2025). Manifeste pour des Études Critiques de l’Intelligence Artificielle. Consulté à l’adresse http://blog.sens-public.org/marcellovitalirosati/manifeste-ecia.html
# Merci !
Déb/u/o/gue tes humanités
CC BY-NC-SA Chaire de recherche du Canada sur les écritures numériques, Bibliothèque des lettres et des sciences humaines, Centre de recherche interuniversitaire sur les humanités numériques. — louis-olivier.brassard@umontreal.ca